一文讲解单片机、ARM、MCU、DSP、FPGA、嵌入式错综复杂的关系!


首先,“嵌入式”这是个概念,准确的定义没有,各个书上都有各自的定义。但是主要思想是一样的,就是相比较PC机这种通用系统来说,嵌入式系统是个专用系统,结构精简,在硬件和软件上都只保留需要的部分,而将不需要的部分裁去。所以嵌入式系统一般都具有便携、低功耗、性能单一等特性。
首先,“嵌入式”这是个概念,准确的定义没有,各个书上都有各自的定义。但是主要思想是一样的,就是相比较PC机这种通用系统来说,嵌入式系统是个专用系统,结构精简,在硬件和软件上都只保留需要的部分,而将不需要的部分裁去。所以嵌入式系统一般都具有便携、低功耗、性能单一等特性。

RA8系列产品具备业界卓越的6.39 CoreMark/MHz测试分数,缩小了MCU与MPU之间的性能差距

Arm Cortex-M 系列被广泛用作汽车微控制器 (MCU) 的主要核心,以及许多汽车 SoC 的配套核心。

继2021年推出Z20K118后,在今年推出Z20K116系列产品。Z20K116M为基于Arm Cortex M0+的增强型微控制器,符合AEC-Q100 Grade1 (–40 °C to 125 °C)规范,满足功能安全ASIL-B,主要面向汽车车身电子、传感器、执行器等应用领域,如电动尾门,HVAC,新能源应用等。

Nordic Semiconductor发布具有多协议短距离无线连接并支持嵌入式机器学习 (ML)的多传感器原型构建平台’Nordic Thingy:53’ (“Thingy:53”),是在最短开发时间内构建具有ML功能的先进无线概念验证原型的理想平台。

IAR Systems®宣布,其最新版本的IAR Embedded Workbench for Arm®增加了对Arm Cortex®-M55处理器的支持。此外,9.20版工具链还新增了对多家半导体厂商的最新微控制器(MCU)的支持。

本应用笔记描述如何在基于Arm® Cortex®‑M33 处理器的Arm® TrustZone® STM32 微控制器上获得安全启动和安全固件更新解决方案。

如果你一直想要为嵌入式开发需求而构建一套基于 ARM 的工作站,那 Adlink 新推出的只有 200×160 毫米的一块微型 COM-HPC 小板,或许就能够满足你对于高性能服务器计算模块的需求。
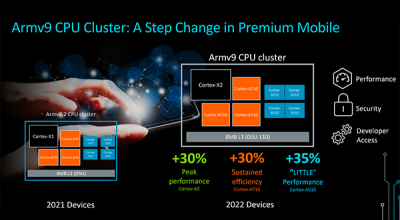
5月26日的发布堪称是 Arm新品发布上里程碑式的发布,因为它开启了一个新的时代!

4月27日,航顺芯片与欧洲著名嵌入式开发软件和工具服务商IAR Systems在深圳航顺总部签署了在ARM、RISC-V应用领域全方位长期深度合作的协议。