ARM
在ARM体系中,通常有以下3种方式控制程序的执行流程:
• 在正常程序执行过程中,每执行一条ARM指令,程序计数器寄存器(PC)的值加4个字节;每执行一条Thumb指令,程序计数器寄存器(PC)的值加2个字节。整个过程是顺序执行。
• 通过跳转指令,程序可以跳转到特定的地址标号处执行,或者跳转到特定的子程序处执行。其中,B指令用于执行跳转操作;BL指令在执行跳转操作的同时,保存子程序的返回地址;BX指令在执行跳转操作的同时,根据目标地址的最低位可以将程序状态切换到Thumb状态;BLX指令执行3个操作:跳转到目标地址处执行,保存了子程序的返回地址,根据目标地址的最低位可以将程序状态切换到Thumb状态。
• 当异常中断发生时,系统执行完当前指令后,将跳转到相应的异常中断处理程序处执行。在当异常中断处理程序执行完成后,程序返回到发生中断的指令的下一条指令处执行。在进入异常中断处理程序时,要保存被中断的程序的执行现场,在从异常中断处理程序退出时,要恢复被中断的程序的执行现场。
ARM体系中异常中断种类:
• 复位(Reset):当处理器的复位引脚有效时,系统产生复位异常中断,程序跳转到复位异常中断处理程序处执行。复位异常中断通常用在下面两种情况:系统加电时和系统复位时。跳转到复位中断向量处执行,称为软复位。
• 未定义指令(Undefined Instruction):当ARM处理器或者是系统中的协处理器认为当前指令未定义时,产生未定义的指令异常中断。
• 软件中断(Software Interrupt SWI):这是一个由用户定义的中断指令。可用于用户模式下的程序调用特权操作指令。在实时操作系统中可以通过该机制实现系统功能调用。
• 指令预取中止(Prefetch Abort):如果处理器预取的指令的地址不存在,或者该地址不允许当前指令访问,当该被预取的指令执行时,处理器产生指令预取中止异常中断。
• 数据访问中止(Data Abort):如果数据访问指令的目标地址不存在,或者该地址不允许当前指令访问,处理器产生数据访问中止异常中断。
• 外部中断请求(IRQ):当处理器的外部中断请求引脚有效,而且CPSR寄存器的I控制位被清除时,处理器产生外部中断请求(IRQ)异常中断。系统中各外设通常通过该异常中断请求处理器服务。
• 快速中断请求(FIQ):当处理器的外部快速中断请求引脚有效,而且CPSR寄存器的F控制位被清除时,处理器产生外部中断请求(FIQ)异常中断。
对异常中断的响应过程(这几点都是ARM核自己已经完成的动作):
• 保存处理器当前状态、中断屏蔽位以及各条件标志为。这是通过将当前程序状态寄存器CPSR的内容保存到将要执行的异常中断对应的SPSR寄存器中实现的。各异常中断有自己的物理SPSR寄存器。
• 设置当前程序状态寄存器CPSR中相应的为。包括:设置CPSR中的位,使处理器进入当前相应的执行模式(处理器模式);设置CPSR中的位,禁止IRQ中断,当进入FIQ模式时,禁止FIQ中断。
• 将寄存器lr_mode设置成返回地址。
• 将程序计数器值(PC),设置成该异常中断的中断向量地址,从而跳转到相应的异常中断处理程序处执行。
从异常中断处理程序中返回(这些返回动作是需要自己写代码完成的):
• 恢复被中断的程序的处理器状态,即将SPSR_mode寄存器内容复制到CPSR中。
• 返回到发生异常中断的指令的下一条指令执行,即将lr_mode寄存器的内容复制到程序计算器PC中。
复位异常中断处理程序不需要返回。在复位异常中断处理程序开始整个用户程序的执行,因而它不需要返回。
转自: uTank
一. 前言
有工程师反应说Keil 下无法使用STM32F4xx 硬件浮点单元, 导致当运算浮点时运算时间过长,还有一些人反应不知如何使用芯片芯片内部的复杂数学运算,比如三角函数运算。针对这个部分本文将详细介绍如何使用硬件浮点单元以及相关数学运算。
二.问题产生原因
1. ------对于Keil MDK Version 5 版本, 编译器已经完全支持STM32F4xx 的FPU(浮点运算单元),可以直接使用芯片内部的浮点运算单元。
2. ------对于Keil MDK Version 4 版本, 高版本v4,比如当前keil 官网可下载的v4.74.0.0 版本也已经支持
FPU,可以直接使用芯片内部浮点运算。但如果使用低版本v4,如v4.23.0.0 版本, 则需要对软件进行相应设置。
三. 如何解决问题
1. 查看手头Keil 版本是否支持FPU,最简单办法是进入Keil 调试界面直接查看0xE000ED88 地址单元数据,如果为0x00F00000, 则说明已经支持FPU,如下图所示:
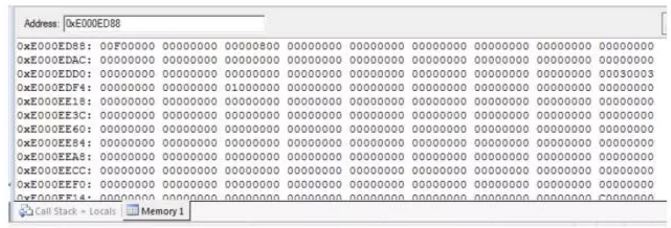
2. 如果0xE000ED88地址数据为0x00000000,则需要做如下操作:
a. 在system_stm32f4xx.c文件中的systeminit()函数里面添加如下代码:
/* FPU settings------------------------------------------------------------*/
#if (__FPU_PRESENT == 1) &&(__FPU_USED == 1)
SCB->CPACR |= ((3UL << 10*2)|(3UL<< 11*2)); /* set CP10 and CP11 Full Access */
#endif
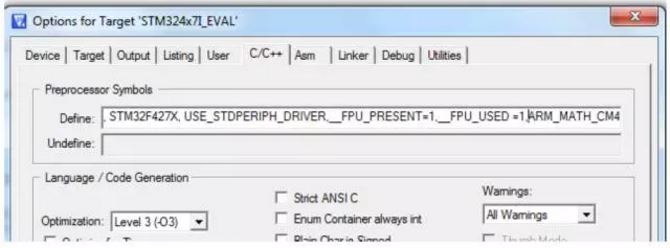
b. 在工程选项(Project->Optionsfor target "XXXX")中的C/C++选项卡的Define 中加入如下的语句,见下图所示:
__FPU_PRESENT=1,__FPU_USED =1。
c. 这样编译时就加入了启动FPU 的代码,CPU 也就能正确高效的使用FPU 进行简单的加减乘除了。
3. 进一步说明使用芯片复杂数学运算使用
对于复杂运算,比如三角函数,开方等运算,需要如下设置:
a. 包含arm_math.h头文件。
b. 在工程选项的C/C++选项卡的define 中继续加入语句ARM_MATH_CM4。
c. 在工程选项的C/C++选项卡的define 中继续加入语句__CC_ARM。
以使用sin,cos 运算举例,需要调用arm_sin_f32()以及arm_cos_f32(),这两个函数定义在
arm_sin_f32.c 和arm_cos_f32.c中,需要在工程中加入这两个c 文件。
* 在 ST 库文件包中的文件目录如下:
\stm32f4_dsp_stdperiph_lib\STM32F4xx_DSP_StdPeriph_Lib_V1.1.0\Libraries\CMSIS\DSP_Lib\Sou
rce\FastMathFunctions
* 在keil 安装目录下的文件目录如下:
\Keil\ARM\CMSIS\DSP_Lib\Source\FastMathFunctions
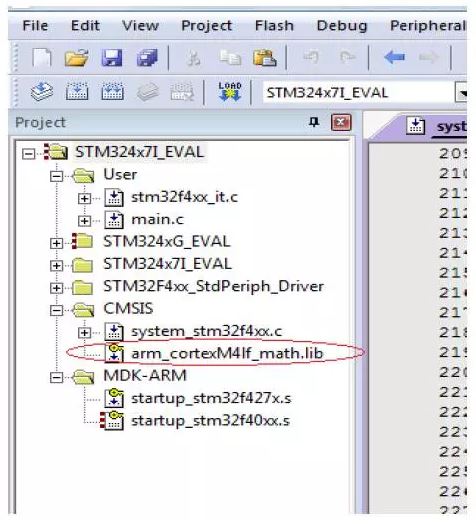
当用到更多数学运算, 如开根号,三角运算,求绝对值等等,客户也可以直接在工程中加入ARM 中的数学运算库arm_cortexM4lf_math.lib,而不需要一个个文件的添加,
* 在 ST 库文件包中的目录如下:
\STM32F4xx_DSP_StdPeriph_Lib_V1.6.0\STM32F4xx_DSP_StdPeriph_Lib_V1.6.0\Libraries\CMSIS\Lib\ARM
* 在keil 安装目录下的文件目录如下:
\Keil\ARM\CMSIS\Lib\ARM
四. 结语
从测试效果看当使用了硬件浮点运算单元,数学计算变得简单高效,可以留给系统更多时间处理其他控制程序,有效提升系统效率,节省时间。
来源: STM32单片机


数据采集系统是通过采样电路将输入的模拟信号转换成离散信号,并送入CPU、MCU或DSP进行处理。现在流行的基于PCI总线设计的采集卡是数据采集系统的主流,其优点是可以利用PCI总线的研究成果快速的开发系统软件,整体运行速度快,能够实现实时采集实时处理。但在一些工业测控现场检测大型设备时,从现场到机房有一定的距离,模拟信号传到安装在PC内的PCI数据采集卡会有不同程度的衰减,且易受工业环境的干扰。而单纯用由微控制器(MCU)为核心的数据采集系统时,把数据采集器置于被监测的设备处,虽然可以避免模拟信号的衰减和被干扰,但在这种数据采集系统中,A/D转换器的启动、读取数据并存入到存储器的整个过程由MCU来参与控制,由于受MCU执行指令时间的限制,采集的速率较低,难以适应高速信号采集的需要。
本文利用ARM微处理器和CPLD器件组成的现场数据采集系统,然后通过以太网接口于上位机相连,就可以有效解决上述问题。
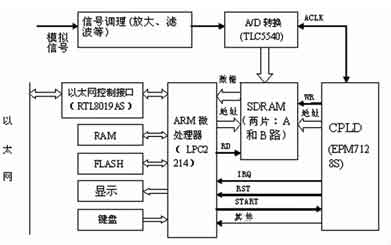
系统的设计方案
整个数据采集系统如图1所示。数据采集系统首先对采集的信号进行前端处理,如信号放大、滤波等预处理。采用的CPLD器件实现整个系统的控制逻辑,它控制着采集通道的切换、A/D转换的起/停、转换后的数据存放在存储单元的地址发生器、产生中断请求以通知ARM读取存放在存储器中的数据,由ARM微处理器进行快速的处理和传输。
1 信号调理模块
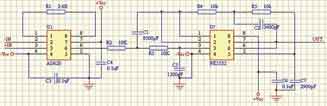
在信号进行数模转换前,在保证被采集信号不失真的前提下,对输入的信号进行放大、滤波等预处理。高速数据采集系统的输入信号通常为高频信号,需要进行阻抗匹配和前置放大,可以选用高速低噪声信号前置放大器和信号变压器。信号前置放大器的优势是:放大系数可变,信号输入的动态范围大,还可以配置成有源滤波器。但放大器的最高工作频率和工作宽带必须满足系统设计的需要,避免信号失真,同时应该考虑放大器引入的噪声损失,为避免对A/D转换器性能的不利影响,前置放大器的信噪比应远大于A/D转换器的信噪比。当频率远远大于100MHz时,尽可能采用信号变压器,其性能指标(如最高工作频率和工作带宽)优于信号放大器,而且信号失真很小,但信号放大系数固定,输入信号的幅度受到限制。该设计中采用前置放大器,其前端的信号调理电路如图2所示。
2 A/D转换模块
将连续信号转换成离散信号进而转换成数字信号以适用于处理的重要芯片是A/D转换器。一般的逐次逼进型A/D转换芯片的转换速度最多在每秒钟几万次,不能满足高速采样的要求。该设计中选择TI公司的TLC5540高速模数转换芯片,其具有8位分辨率,内置采样和保持电路,该芯片采用一种改进的半闪结构、CMOS工艺制造,因而大大减少了器件中比较器的数量,而且在高速转换的同时,能够保持低功耗,转换速率可达40Mb/s。
TLC5540以流水线的工作方式进行工作,在每一个CLK周期均启动一次采样,完成一次采样,每次启动采样是在CLK的下降沿进行,第n次采样的数据经过3个时钟周期的延迟之后,送到内部数据总线上,所以系统刚启动时读取的3个数据是无效数据,在软件设计时,必须抛弃系统启动时读取的前3个数据。
3 CPLD模块
该设计中采用ALTERA公司的EPM7128S, 它实现整个系统的控制逻辑。主要有下面几个控制模块电路构成:
● 时钟控制电路,提供A/D转换器的时钟信号(ACLK),该信号同时提供了给存储器的WR,以控制整个系统的采样频率。
● 地址产生电路,生成SRAM的地址控制信号,每写完一次SRAM, 地址自动加1。
● 地址总线切换电路,对内部地址发生器和LPC2214产生的两组地址进行切换,提供给存储器。当处于写存储器时,存储器的地址由内部地址发生器发生;当处于LPC2214读存储器时,存储器的地址由LPC2214的地址总线提供。
● 数据总线切换电路,对A/D的数据线和LPC2214的数据总线进行切换,当写数据时,使数据从A/D输出到存储器,读数据时,使数据从存储器读到LPC2214的数据总线。
● 地址译码及逻辑控制电路,完成对系统地址总线的译码,产生各种必须的控制信号。
4 MCU模块
该设计中采用Philips公司的LPC2214的微处理器,用它来对采集到的数据进行存储、显示、处理操作,并作为系统与上位机沟通的桥梁。LPC2214是基于ARM7TDMI核的RISC微处理器,ARM7TDMI为低功耗、高性能的16/32位核,最适合对价格及功耗敏感的场合。LPC2214在ARM7TDMI核的基础上扩展了一系列通用外围器件,使其特别适用于工业控制、医疗系统、访问控制,由于内置了宽范围的串行通信接口,使其也非常适用于通信网关、协议转换器、嵌入式软MODEM以及其他类型的应用。
5 ARM与网卡芯片接口设计
为使采集到的数据或处理后的数据传送到上位机,需在系统中增加以太网接口,通常有两种方法:
(1)ARM微处理器+网络控制器,这种方法对处理器没有特殊的要求,只要把以太网芯片连接到处理器的总线上即可,此方法的通用性较强,不受处理器的限制;
(2)采用带以太网接口的ARM微处理器,但通常这种处理器往往是面向网络应用而设计的,不是特别适用于工业领域。故该设计中选用第一种方法。
网路控制器RTL8019AS是目前比较常用的10Mb/s嵌入式以太网控制芯片,在芯片内部集成了DMA控制器,ISA总线控制器和16KB SRAM,网路PHY收发器。用户可以通过DMA方式把需要发送的数据写入片内SRAM中,让芯片自动将数据发送出去;而芯片在接受到数据后,用户也可以通过DMA方式将其读出。
系统基本工作原理
数据采集器置于被监控的设备处,对传送过来的模拟信号进行信号调理,LPC2214启动系统数据采集,CPLD控制器输出一个脉冲给A/D转换器的CLK端,使其开始第n次A/D转换,同时将CPLD内部地址发生电路产生的地址信号经地址选择器直接送到存储器,A/D转换器所采集到的第n-3次的数据经数据总线直接输入到存储器中保存。
由于采样频率高,用CPLD将采样数据存储到两路同步动态存储器(SDRAM)中。CPLD先把采集到的数据以DMA的方式存储到A路SDRAM中。 等数据写满A路SDRAM后,由CPLD器件引起LPC2214外部中断,LPC2214进入中断处理程序,读取SDRAM中的数据,并进行处理,同时CPLD将接下来采集到的数据以DMA的方式存储到B路SDRAM中, 等存储器B数据装满后,CPLD器件引起LPC2214外部中断,LPC2214进入中断处理程序,读取B路SDRAM中的数据,并进行处理,如此循环下去,完成数据的接收和传输并行。
可以看到ARM微处理器只控制数据采集的启动和对采集到的数据进行快速处理和传输,在数据采集的过程中,ARM微处理器不对采集通道进行任何控制,完全由硬件自动实现数据采集的全过程,实现了高速数据采集的目的。
系统软件设计
软件部分要分别编写LPC2214的处理模块程序和CPLD的控制模块程序,LPC2214的程序包括嵌入式操作系统μC/OS-II和各应用程序的编写,CPLD控制模块程序用VHDL语言来实现。
在编写处理器的处理程序时,如采用单任务顺序机制,系统的安全性差,这对于稳定性、实时性要求高的数据采集系统是不允许的,因此根据整个装置实现的功能和对它的要求进行系统任务的分割,并分配优先级,由操作系统来进行管理调度。本设计选用μC/OS-II操作系统,μC/OS-II V2.52已通过美国航空航天管理局(FAA)的安全认证,其采用优先级调度算法完成任务间的调度,支持抢占式调度,具有执行效率高、占有空间小、实时性能优良和扩展性强等特点,其内核还提供信号量、消息邮箱、消息队列、内存管理等系统服务。程序架构如图3所示。
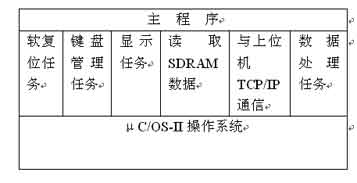
根据应用,本系统分为以下几个任务:软复位任务(程序对系统初始状态进行重新设定),对SDRAM的读取、与上位机的TCP/IP通信、显示任务、键盘管理任务和数据处理任务,任务间的通信通过消息队列来完成。系统中的每个任务包括应用程序、任务堆栈和任务控制块三部分。任务控制块是一个数据结构,当任务的CPU使用权被剥夺时,μC/OS-II用它来保存该任务的状态,当任务重新获得CPU的使用权时,任务控制块能确保任务从被中断的那一点执行下去,操作系统可以通过查询任务控制块的内容从而对任务进行调度管理。
在用μC/OS-II作为内核来编写数据采集系统系统的应用软件之前,必须完成μC/OS-II在微处理器的移植工作,由于μC/OS-II在设计之初就充分考虑了在不同处理器上的移植问题,其结构化设计把与处理器相关的部分分离出来,因此在任何处理器上的移植 μC/OS-II都只需要关心三个文件:头文件OS_CPU.H、文件OS_CPU_C.C和汇编文件OS_CPU_A.ASM。
为了满足系统与以太网直接交换信息的需要,本设计在μC/OS-II中移植了LWIP(Light Weight IP轻型IP协议)协议栈。LWIP是瑞士计算机科学院Adam Dunkels等开发的一套用于嵌入式系统的开放源代码TCP/IP协议栈。LWIP可以移植到操作系统上,也可以在无操作系统的情况下运行,LWIP实现的重点是在保持TCP协议主要功能的基础上减少对RAM的占用,一般它只需要几十字节的RAM和40Kb左右的ROM就可以了。
LWIP可以很容易地在μC/OS-II的调度下,为系统增加网络通信和网络管理功能。LWIP把所有与硬件、操作系统、编译器相关的部分独立出来,放在/SRC/arch目录下,因此LWIP在 μC/OS-II上的移植修改这个目录下的文件即可。
结论
在ARM微处理器中移入嵌入式实时操作系统μC/OS-II,使系统的稳定性、实时性得到保证,实时操作系统将应用分解成多任务,简化了应用系统软件的设计;采用CPLD器件集成了电路的全部控制功能,摆脱了单纯用由微控制器为核心的数据采集系统时的速度瓶颈,极大提高了数据采集速度。整个系统具有速度高、实时性好、抗干扰能力强、性价比高等特点。
转自:广电电器


1、软件方面
这应该是最大的区别了。引入了操作系统。为什么引入操作系统?有什么好处?
1)方便。主要体现在后期的开发,即在操作系统上直接开发应用程序。不像单片机一样一切都要重新写。前期的操作系统移植工作,还是要专业人士来做。
2)安全。这是LINUX的一个特点。LINUX的内核与用户空间的内存管理分开,不会因为用户的单个程序错误而引起系统死掉。这在单片机的软件开发中没见到过。
3)高效。引入进程的管理调度系统,使系统运行更加高效。在传统的单片机开发中大多是基于中断的前后台技术,对多任务的管理有局限性。
2、硬件方面
现在的8位单片机技术硬件发展的也非常得快,也出现了许多功能非常强大的单片机。但是与32arm相比还是有些差距吧。
arm芯片大多把SDRAM,LCD等控制器集成到片子当中。在8位机,大多要进行外扩。
总的来说,单片机是个微控制器,arm显然已经是个微处理器了。
引入嵌入式操作系统之后,可以实现许多单片机系统不能完成的功能。比如:嵌入式web服务器,java虚拟机等。也就是说,有很多免费的资源可以利用,上述两种服务就是例子。如果在单片机上开发这些功能可以想象其中的难度。
初学者如何选择ARM开发硬件?
1. 如果你有做硬件和单片机的经验,建议自己做个最小系统板:假如你从没有做过ARM的开发,建议你一开始不要贪大求全,把所有的应用都做好,因为ARM的启动方式和dsp或单片机有所不同,往往会碰到各种问题,所以建议先布一个仅有Flash,SRAM或SDRAM、CPU、JTAG、和复位信号的小系统板,留出扩展接口。使最小系统能够正常运行,你的任务就完成了一半,好在arm的外围接口基本都是标准接口,假如你已有这些硬件的布线经验,这对你来讲是一件很轻易的事情。
2. 动手写启动代码,根据硬件地址先写一个能够启动的小代码,包括以下部分:
初始化端口,屏蔽中断,把程序拷贝到SRAM中;完成代码的重映射;配置中断句柄,连接到C语言入口。也许你看到给你的一些示例程序当中,bootloader会有很多东西,但是不要被这些复杂的程序所困扰,因为你不是做开发板的,你的任务就是做段小程序,让你的应用程序能够运行下去
3.假如你是作硬件,每个厂家基本上都有针对该芯片的DEMO板原理图。先将原理图消化。这样你以后做设计时,对资源的分配心中有数。器件的DATSHEET一定要好好消化。
4. 仔细研究你所用的芯片的资料,尽管arm在内核上兼容,但每家芯片都有自己的特色,编写程序时必须考虑这些问题。尤其是女孩子,在这儿千万别有依靠心理,总想拿别人的示例程序修改,却越改越乱。
5. 多看一些操作系统程序,在arm的应用开放源代码的程序很多,要想提高自己,就要多看别人的程序,linux,uc/os-II等等这些都是很好的原码。
6.假如做软件最好对操作系统的机理要有所了解。当然这对软件工程师来说是小菜一碟。但假如是硬件出身的就有点费劲。
转自:Avatarx
随着电子信息技术和半导体技术的深入发展,嵌入式系统的应用日趋广泛,在控制领域之中更多的使用了高性能微处理器,以满足各方面越来越多的控制应用需求。基于ARM嵌入式平台的数字调压控制系统,克服了传统上以旋钮或滑变式变阻器对交流电压进行模拟控制的弊端。本系统以嵌入式技术为基础,在嵌入式平台上利用ARM微处理器实时控制数模信号的转换,以控制正弦波调压模块对交流电压的大小调节。本文中通过对本系统的实际测试,验证了数字调压控制系统的功能特性,并且定量测试得出了本系统可以实现对交流电压进行线性调节的结论。数字调压控制系统可作为对电压的智能调节装置应用于家庭、医疗及工业自动化等领域,并且具有调节精度高、调节线性度好,易于操作等特性。
调压控制系统作为对电压的智能调节管理装置常用于家庭、医疗和工业自动化控制等领域。以往对交流电压的控制调节通常使用滑动式或旋钮式变阻器串接入电压回路中实现,旋钮的长时间旋转会导致调节不灵敏甚至失效,调节的精度降低,误差较大。随着电子科技和嵌入式技术的迅猛发展,嵌入式系统越来越多的应用于控制领域之中,在嵌入式平台上实现数字智能控制的调压系统有着重要的意义。文中选用ARM Cotrex—A8微处理器搭建硬件控制平台,使用Linux作为嵌入式操作系统,实时性强,易于开发。
1 ARM数字调压控制系统的总体设计
ARM数字调压控制系统的硬件设计主要包括硬件的总体设计、处理器的选型以及硬件的详细设计。ARM数字调压控制系统总体设计阶段主要任务是依照嵌入式系统的设计流程,明确系统需要实现的功能,对系统进行硬件模块划分,系统硬件结构框架确定之后选定处理器型号,搭建开发环境已完成本系统的设计目标。
1.1 ARM数字调压控制系统的结构
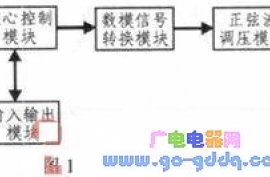
系统的硬件总体设计是以系统的功能需求为基础的。本系统的研究目标是ARM数字调压控制系统,需要实现通过数字信号控制来完成对交流电压的智能调节。一个完整的数字式调压控制系统包括了核心控制模块、数模信号转换模块、输入输出模块和正弦波调压模块四个部分组成。系统结构框图如图1所示。用户从输入输出模块输入指令给控制模块,控制模块收到指令后控制数模转换模块执行数字信号到模拟信号的转换,转换结果输出给正弦波调压模块。
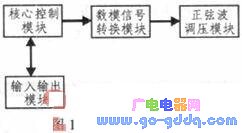
核心控制模块主要包括ARM处理器、内存、NANDFlash、电源管理模块等,数字调压控制系统的所有控制操作均由处理器来完成。处理器配有512MB的DDR2内存,SD卡用来存储Linux系统内核镜像、文件系统、驱动程序和应用程序,系统上电后Bootloader将引导操作系统的启动,并将应用程序装载到内存中运行。
数模信号转换模块主要包括高精度数模转换芯片,选用DAC7311来实现数字控制信号到模拟控制信号的转换工作,其转换精度高达12位,通过串行同步接口与处理器相连接。
输入输出模块作为用户与系统的交互接口,主要包括一块LCD触摸屏、用户按键,用来显示系统相关信息、应用程序界面和控制程序的运行等。
正弦波调压模块与数模信号转换模块相连接,经过数模转换后输出的模拟控制信号输出到正弦波调压模块上,来实现对交流电压的大小调制。
1.2 微处理器选型
本系统中核心控制模块的主要器件是嵌入式微处理器。在嵌入式微处理器选型时依次要考虑微处理器的性能、技术指标、功耗及所支持的开发工具等。在PCB设计时主要考虑到处理器的封装和Layout设计时布局、布线的难易程度和制版时的费用等问题。依据本系统的设计目标和功能需求,并综合了设计过程中的相关因素,本次设计选择了德州仪器推出的ARM嵌入式微处理器AM3354。AM3354外设资源丰富,处理性能优越,并且功耗小,成本低。AM3354提供两种形式封装,298个引脚ZCE封装,焊球间距0.65 mm;324个引脚ZCZ封装,焊球间距0.80 mm。依据PCB设计原则本设计中选用324个引脚ZCZ封装芯片。
2 ARM数字调压控制系统的硬件设计
系统的硬件设计主要描述硬件系统的实现方法。嵌入式硬件设计的思想是以实际应用为中心,硬件系统可裁剪,根据实际应用可进行功能的扩展,以满足成本、功耗及产品体积的综合需求。系统基本实现方法为系统上电启动后Bootloader从SD卡中将Linux操作系统和应用程序文件读入内存中,并运行操作系统。系统内存使用了两片256M的MT74H256M8,总共内存512M。当用户控制应用程序发出指令后,处理器通过配置GPIO接口模拟串行同步接口来控制数模转换模块进行数字信号到模拟信号的转换。
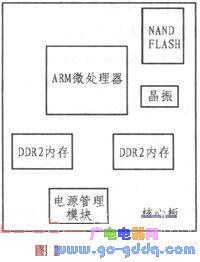
2.1 核心板设计
本系统中核心板采用6层板设计。在硬件设计中,多层板主要用来降低硬件设计成本,缩小电路板的面积。由于核心板上拥有DDR2内存,属于高速电路,因此内存电路是核心板设计的重点和难点。核心板的硬件结构如图2所示。由图可见,处理器外挂两条内存,两条内存共享处理器的时钟线、数据线和地址线,为了保证系统稳定性,两条内存到处理器的走线采用T型连接设计,并且等长布线。为了避免对高速电路的影响,晶振应避开高速电路,尽可能的靠近处理器的时钟引脚。电源管理模块负责对核心板上所有器件的供电管理。
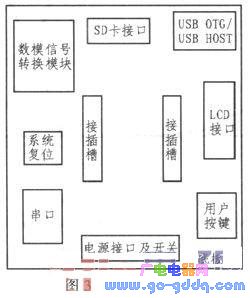
2.2 底板设计
本设计中底板采用2层板设计,底板上主要包括了外围设备接口、数模信号转换模块和插槽,外围接口电路包括系统复位电路、串口电路、SD卡接口电路、LCD触摸屏接口电路、USB接口电路、电源开关电路和用户自定义按键,底板上的接插槽作为接口与核心板连接,底板的系统结构框图如图3所示。数模转换模块主要由高精度数模转换芯片组成,使用串行接口连接。底板上所有部件接口引脚均连接至接插槽上,通过插槽与核心板连接,这样有利于后期功能的扩展和系统的裁剪,同时有效的降低了开发成本。
3 PCB的板级设计与仿真
当完成系统的硬件设计和原理图绘制之后,开始进行PCB电路板设计,本系统的PCB设计使用Cadence 16.3进行。进行PCB板级设计之前应做好如下准备工作:做好元器件的模型库和元器件的封装,设计PCB板。根据前文所述,本系统硬件采用底板加核心板的设计方法,因此要根据实际需求的尺寸分别设计底板和核心板的PCB板,设计板子的叠层,根据需求核心板设置为6层板,底板设置为2层板,之后进行布局和布线操作。由于本系统中内存和处理器之间的电路属于高速电路,因此需要对内存的时钟线及数据线进行仿真,来验证布线的正确性,仿真使用Allegro PCB SI GXL进行。
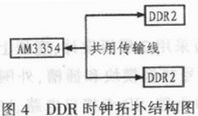
DDR时钟线是内存电路中最重要的线路,布线时采用差分对走线。仿真时打开本设计的PCB文件,首先建立DDR时钟的差分对,之后进行仿真前的参数设定,包括板子的叠层设置、差分阻抗设置、测量差分缓冲延迟及为内存和处理器分别分配SI模型。由于Cadence PCB SI在仿真过程中使用的是DML模型,因此在仿真前需要将器件的IBIS模型进行验证,没有错误后转换成DML模型,然后添加到模型库的路径之下。在测量差分缓冲延迟时,在处理器模型的引脚列表中找到DDR时钟的两个引脚,并进行引脚的耦合设置。上一步完成之后,开始进行内存时钟差分对的仿真。首先设置互连模型参数,使用SigXplorer PCB SI GXL进行拓扑的提取。打开约束管理器,选中DDR时钟的差分对,提取其拓扑结构,如图4所示。
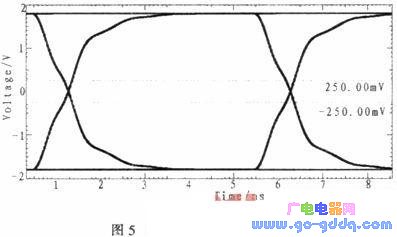
然后对相关仿真参数和差分驱动器激励进行设置,设置完成后使用无损互连分析对内存时钟差分对进行仿真。波形的眼图如图5所示。
使用如上同样的方法对内存数据线进行波形图和波形的眼图仿真,依据得到的眼图判定布线是否合理得当,若眼图较乱则需要调整布线,之后再进行仿真验证。
4 ARM数字调压控制系统的软件设计
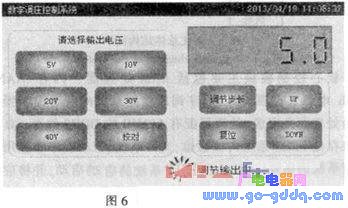
ARM数字调压控制系统使用Linux操作系统,系统应用程序软件在Qt 4.0环境下开发。系统启动后自动运行应用程序,其主界面如图6所示。界面中预置了固定电压输出按钮、步长调节按钮、微调按钮、复位按钮和输出校对按钮。程序中提供了两种不同的步进调节长度,步进可选为1 V或5 V步进。系统启动后默认为1V步进长度。按复位键后输出电压被清零。
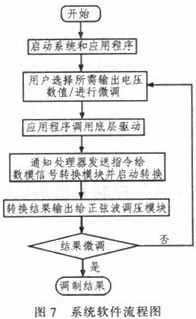
本系统的软件流程图如图7所示。当使用本系统进行数字调压控制的时候,首先启动本系统,待系统正常上电启动后,系统自动运行控制应用程序,用户通过可视化的输入界面选择需要输出的电压值,用户选择后应用程序调用底层驱动程序将指令数据传递给处理器进行处理,处理器接到调用请求后将指令数据通过同步串行接口发送给数模信号转换模块,转换结果输出给正弦波调压模块以得到所需的电压值;同时也可通过up、down调节按钮对输出电压进行微调,直到得到理想的输出值为止。复位键用来对调压模块进行复位,使得输出端压降为0 V。数模信号转换过程中使用的公式如下:
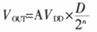
其中,n为转换精度,此处等于12;D为二进制指令代码,12位长度;AVDD为参考电压值,等于5 V;VOUT为调制输出电压值,范围是0~5 V。
5 实验结果
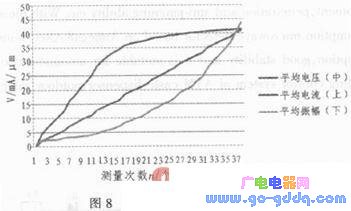
对于本系统的测试分两步进行。首先将家用节能灯泡连接至正弦波调压模块的输出端,检查连接无误后打开系统开关,上电启动系统。首先按复位键,将输出清零,此时灯泡处于熄灭状态,之后连续按下“up”键将看到灯泡逐渐变亮,相反按下“down”键灯泡逐渐变暗直到完全熄灭。本步实验的目的是进行系统的功能验证,即验证本系统是否存在调压功能。本次试验结束后,将灯泡取下,将振动器连接至正弦波调压模块的输出端,本步实验的目的是定量测试系统调压功能是否具有线性特性。同样方法检查连接无误后上电启动系统,系统启动后按下复位键,将输出端电压清零。此时连续按下“up”键,使电压从0 V开始逐渐增大,然后反方向按下“down”键,使电压逐渐减小到0 V,测试过程中使用万用表测量输出端电压和电流,并使用测振仪测量振动器的振动幅度,记录测量结果。本次试验反复测量4次,每次记录37次
结果,将4次测量结果取平均值,并绘制电压、电流及对应振动幅度的变化趋势如图8所示。
6 结论
文中详细描述了基于ARM的数字调压控制系统的设计流程及实现方法,并进行了试验检测。通过第一步测试证明了本系统对电压调节控制的有效性,而第二步测试结果的变化趋势图表明,输出端电压呈明显线性变化,电流在线性增大到一定数值后变化趋缓。而在电压、电流的共同影响下振动幅度呈指数上升趋势变化,由于受到测振仪的测量精度限制,5微米以下振幅变化较缓,敏感度较低,5微米以上振动幅度呈较明显线性上升变化趋势。
文中所述的数字调压控制系统可以实现理想的线性调压控制,具有调节精度高、速度快、易于操作使用等优点,在后期的改进中仍需要对调节误差进行控制,使精确度进一步增大。在应用控制软件上根据实际控制需求进行功能的扩展与优化。
转自: 广电电器








x86和arm在原子操作上有些差别,下面一代码的形式来说明区别:
首先比较单核:
由于x86是CISC指令集,允许在一条指令里进行两次内存操作,所以对i++,i__这些操作在单核条件下是原子,当然必须得是显示使用addl r,%1这种,就可在一条指令里完成读,写操作。
而arm属于RISC指令集,在一次指令执行期间只能有一次内存操作,所以像i++,i--这些需要先读取内存值然后赋值的操作,在arm架构下没法一条指令完成,所以就不满足原子操作,这时怎样实现原子操作呢:
我们通过代码来看;
对于atomic_add
x86的实现很简单:
static __inline__ void atomic_add(int i, atomic_t *v)
{
__asm__ __volatile__(
LOCK "addl %1,%0"
:"=m" (v->counter)
:"ir" (i), "m" (v->counter));
}单核情况下LOCK是空。
下面再看下atomic_add_and_test:
static __inline__ int hal_atomic_add_and_test(int i, emcos_atomic_t *v)
{
unsigned char c;
__asm__ __volatile__(
LOCK "addl %2,%0; sete %1"
:"=m" (v->val), "=qm" (c)
:"ir" (i), "m" (v->val) : "memory");
return c;
}可能大家会想,这个有两条指令了,能是原子的吗?肯定是,为什么是呢?
大家要注意sete %1这个是条件指令,而这个条件(cflags)是进程相关的,即使当进程执行完add1 %2,%0,这时发生中断,切换到另外一个进程,当回来的时候cflags还是进程的,和没切换的情形一样,所以是原子。
而对于arm这需要更多工作:
#define atomic_add(i, v) (void) atomic_add_return(i, v)
static inline int atomic_add_return(int i, atomic_t *v)
{
unsigned long flags;
int val;
local_irq_save(flags);
val = v->counter;
v->counter = val += i;
local_irq_restore(flags);
return val;
}上面可以看出是通过关中断来实现的,为什么要关中断来实现原子操作:
分析下:
arm对于i++会生成如下代码:
1 ldr r0,=i
2 mov [r0],r1 //这个读内存操作
3 inc r1 //如果在这个时候发生中断,然后在中断处理程序中也执行i++操作就不是原子操作
4 mov r1,[r0] //这个写内存操作
假设I=0。如果进程1执行i++,执行到3时被中断打断,然后中断中也执行了i++,当两个i++执行完了,i=1,而不是我们所要的2,这就是非原子操作的结果。
怎么解决,就是说2-4这段代码要么不执行,要么执行完才能保证原子,这个在单核上通过关中断就可以实现,这也是上面关中断的原因。
2.多核情况;
x86架构下:
单指令也不是原子操作了,比如addl r,%1这种有两次内存操作的也不是原子操作,有可能在执行下一次内存操作的时候,另一个核心也读取了这个内存,也会造成两次i++操作为1的错误结果。
解决方法是家LOCK标识,这个标识的作用是在一条指令执行时,锁住总线,其他核心没法读取,从而得到了原子操作。
arm架构下:
arm只有v6系列后的才有多核,也才有专门的内存原子操作机制就是ldrex,strex指令。
其源码如下:
static inline int atomic_add_return(int i, atomic_t *v)
{
unsigned long tmp;
int result;
__asm__ __volatile__("@ atomic_add_return\n"
"1: ldrex %0, [%2]\n"
" add %0, %0, %3\n"
" strex %1, %0, [%2]\n"
" teq %1, #0\n"
" bne 1b"
: "=&r" (result), "=&r" (tmp)
: "r" (&v->counter), "Ir" (i)
: "cc");
return result;
}转自: eeworld.com
ARM处理器简介及RISC特点
ARM处理器简介
ARM(Advanced RISC Machines)是一个32位RISC(精简指令集)处理器架构,ARM处理器则是ARM架构下的微处理器。ARM处理器广泛的使用在许多嵌入式系统。ARM处理器的特点有指令长度固定,执行效率高,低成本等。
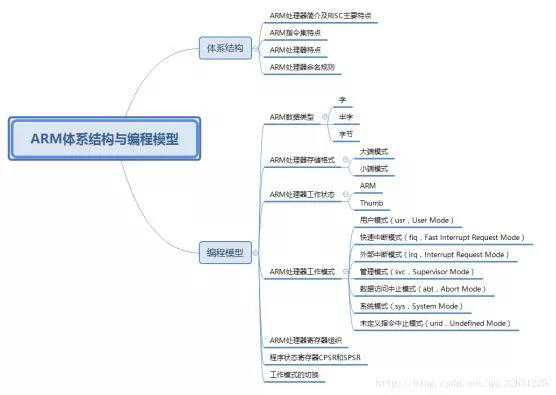
RISC设计主要特点
1、指令集——RISC减少了指令集的种类,通常一个周期一条指令,采用固定长度的指令格式,编译器或程序员通过几条指令完成一个复杂的操作。而CISC指令集的指令长度通常不固定。
2、流水线——RISC采用单周期指令,且指令长度固定,便于流水线操作执行。
3、寄存器——RISC的处理器拥有更多的通用寄存器,寄存器操作较多。例如ARM处理器具有37个寄存器。
4、Load/Store结构——使用加载/存储指令批量从内存中读写数据,提高数据的传输效率。
5、寻址方式简化,指令长度固定,指令格式和寻址方式种类减少。
ARM指令集特点
ARM处理器是基于RISC的,但不是纯粹的RISC体系结构。为了使ARM处理器能够更好的满足嵌入式系统的需要,ARM指令集和单纯的RISC指令集有以下几点不同:
1、一些特定的指令周期数可变。例如多寄存器装载或存储的Load/Store指令执行周期就是不确定的,这个会根据相关的寄存器个数而定。如果是访问连续的内存地址,就可以改善性能,因为连续的内存访问比随机访问要快。根据这个特点,由于在函数的起始和结尾通常会有多个寄存器与内存进行数据交换的操作,因此相应操作的指令条数会减少,提高了代码的密度。
2、内嵌的桶形移位寄存器产生了更复杂的指令。桶形移位寄存器是一个硬件部件,在一个寄存器被一条指令使用之前,桶形移位寄存器可以处理这个寄存器中的数据。桶形移位寄存器扩展了许多指令的功能,以此改善内核的性能,提高代码密度。
3、Thumb16位指令集。ARM处理器有两种工作状态,一种是ARM状态,一种是Thumb状态。ARM状态下指令长度为32位,Thumb状态下指令长度为16位。这种特点使得ARM既能执行16位指令,又能执行32位指令,从而增强了ARM内核的功能。
4、条件执行。只有当某个特定条件满足时指令才会被执行。这个特性可以减少分支指令的数目,从而改善性能,提高代码密度。
5、增强指令。一些功能强大的数字信号处理器(DSP)指令被加入到标准的ARM指令中,以支持快速的16*16乘法操作及饱和运算。ARM的这些增强指令,使得ARM处理器不需要加上DSP即可实现。
ARM处理器特点
1、ARM指令都是32位定长的
2、寄存器数量丰富(37个寄存器)
3、普通的Load/Store指令
4、多寄存器的Load/Store指令
5、指令的条件执行
6、单时钟周期中的单条指令完成数据移位操作和ALU操作
7、通过变种和协处理器来扩展ARM处理器的功能
8、扩展了16位的Thumb指令来提高代码密度
ARM处理器命名规则
ARM编程模型

1、字(Word):在ARM体系结构中,字的长度为32位。
2、半字(Half-Word):在ARM体系结构中,半字的长度为16位。
3、字节(Byte):在ARM体系结构中,字节的长度为8位。
ARM处理器存储格式
ARM体系结构将存储器看作是从0地址开始的字节的线性组合。作为32位的微处理器,ARM体系结构所支持的最大寻址空间为4GB。
ARM体系结构可以用两种方法存储字数据,分别为大端模式和小端模式。
大端模式(高地高低):字的高字节存储在低地址字节单元中,字的低字节存储在高地址字节单元中。
小端模式(高高低低):字的高字节存储在高地址字节单元中,字的低字节存储在低地址字节单元中。
ARM处理器工作状态
从编程的角度来看,ARM微处理器的工作状态一般ARM和Thumb有两种,并可在两种状态之间切换。
1、ARM状态:此时处理器执行32位的字对齐ARM指令,绝大部分工作在此状态。
2、Thumb状态:此时处理器执行16位的半字对齐的Thumb指令。
ARM处理器工作模式
1、用户模式(usr,User Mode):ARM处理器正常的程序执行状态。
2、快速中断模式(fiq,Fast Interrupt Request Mode):用于高速数据传输或通道处理。当触发快速中断时进入此模式。
3、外部中断模式(irq,Interrupt Request Mode):用于通用的中断处理。当触发外部中断时进入此模式。
4、管理模式(svc,Supervisor Mode):操作系统使用的保护模式。在系统复位或执行软件中断指令SWI时进入。
5、数据访问中止模式(abt,Abort Mode):当数据或指令预取中止时进入该模式,可用于虚拟存储及存储保护。
6、系统模式(sys,System Mode):运行具有特权的操作系统任务。
7、未定义指令中止模式(und,Undefined Mode):当未定义的指令执行时进入该模式,可用于支持硬件协处理器的软件仿真。
除了用户模式之外,其余六种模式都是特权模式。除了用户模式和系统模式之外,其余五种模式都是异常模式。
在特权模式下程序可以访问所有的系统资源。非特权模式和特权模式之间的区别在于有些操作只能在特权模式下才被允许,例如直接改变模式和中断使能等。而且为了保证数据安全,一般MMU会对地址空间进行划分,只有特权模式才能访问所有的地址空间。而用户模式如果需要访问硬件,必须切换到特权模式下,才允许访问硬件。
ARM处理器寄存器组织
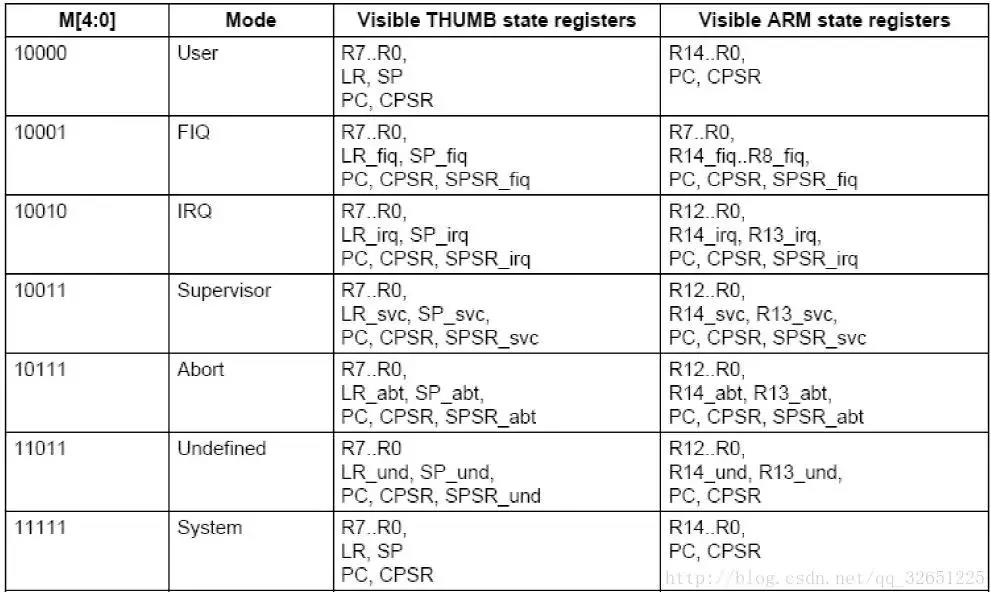
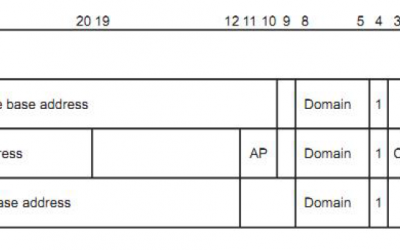
ARM共有37个32位寄存器,其中31个为通用寄存器,6个为状态寄存器,包括
R0-R15,R8_fiq-R14_fiq,R13_svc,R14_svc,R13_abt,R14_abt,R13_irq,R14_irq,R13_und,R14_und,CPSR,SPSR_fiq,SPSR_svc,SPSR_abt,SPSR_irq,SPSR_und。如图。
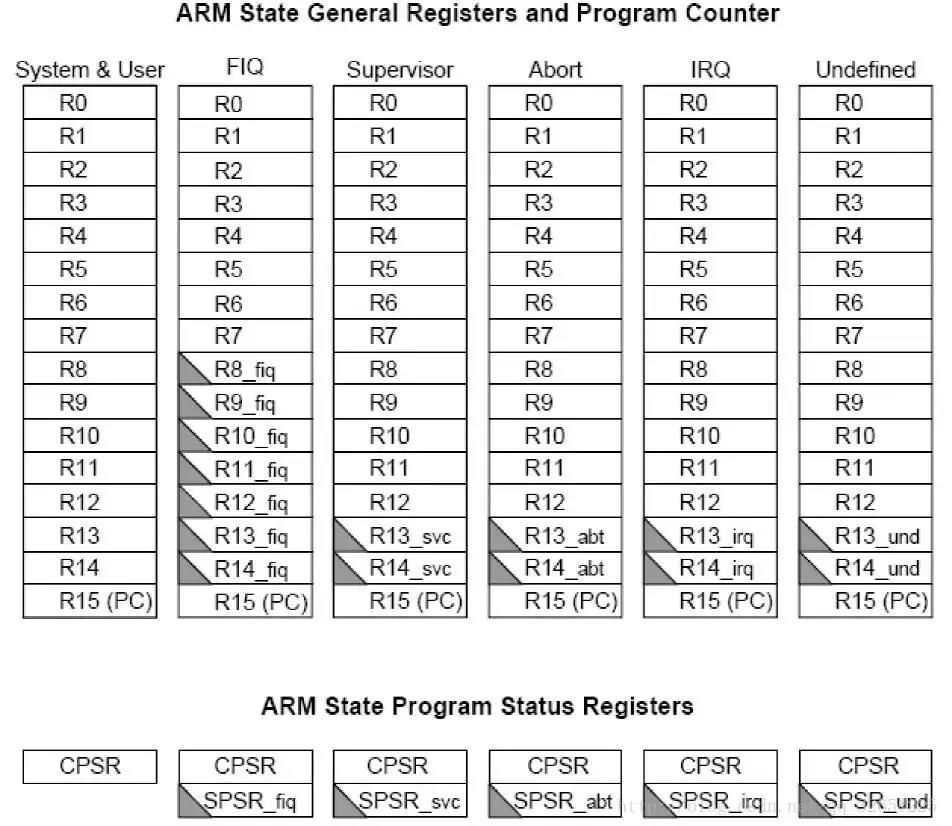
通用寄存器包括R0-R15,可以分为3类:
1.未分组寄存器R0-R7
在所有运行模式下,未分组寄存器都指向同一个物理寄存器,他们未被系统用作特殊的用途。因此在中断或异常处理进行异常模式转换时,由于不同的处理器运行模式均使用相同的物理寄存器,所以可能造成寄存器中数据的破坏。
2.分组寄存器R8-R14
对于分组寄存器,他们每次所访问的物理寄存器都与当前的处理器运行模式相关。具体如上图。
R13常用作存放堆栈指针,用户也可以使用其他寄存器存放堆栈指针,但在Thumb指令集下,某些指令强制要求使用R13存放堆栈指针。
R14称为链接寄存器(LR,Link Register),当执行子程序时,R14可得到R15(PC)的备份,执行完子程序后,又将R14的值复制回PC,即使用R14保存返回地址。
3.程序计数器PC(R15)
寄存器R15用作程序计数器(PC),在ARM状态下,位[1:0]为0,位[31:2]用于保存PC;在Thumb状态下,位[0]为0,位[31:1]用于保存PC。
由于ARM体系结构采用了多级流水线技术,对于ARM指令集而言,PC总是指向当前指令的下两条指令的地址,即PC的值为当前指令的地址值加8个字节。
程序状态寄存器CPSR和SPSR
CPSR(Current Program Status Register,当前程序状态寄存器),CPSR可在任何运行模式下被访问,它包括条件标志位、中断禁止位、当前处理器模式标志位以及其他一些相关的控制和状态位。
每一种运行模式下都有一个专用的物理状态寄存器,称为SPSR(Saved Program Status Register,备份的程序状态寄存器),当异常发生时,SPSR用于保存当前CPSR的值,从异常退出时则可由SPSR来恢复CPSR。
由于用户模式和系统模式不属于异常模式,这两种状态下没有SPSR,因此在这两种状态下访问SPSR,结果是未知的。
CPSR保存数据的结构:
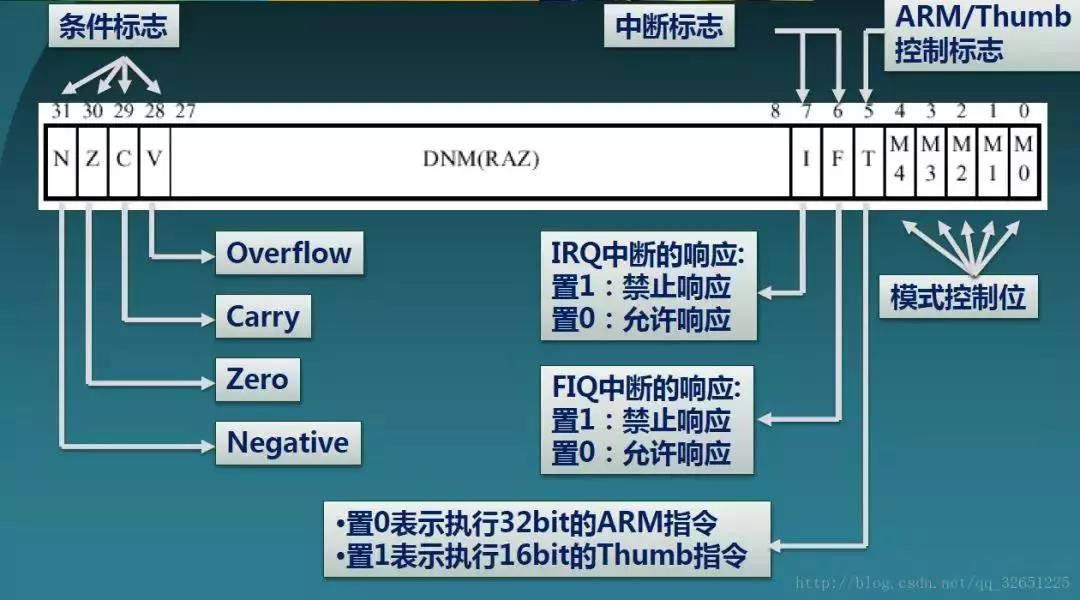
1.N(Negative):当用两个补码表示的带符号数进行运算时,N=1表示结果为负,N=0表示结果为正数或零。
2.Z(Zero):Z=1表示运算结果为0,Z=0表示运算结果非零。
3.C(Carry):有4种方法可以设置C的值:
(1)加法指令(包括比较指令CMP)
(2)当运算产生进位时(无符号数溢出),C=1,否则C=0
(3)减法运算(包括比较指令CMP)
(4)当运算产生了借位(无符号数溢出),C=0,否则C=1
对于包含移位操作的非加/减运算指令,C为移出值的最后一位。对于其他的非加/减运算指令,C的值通常不变。
4. V(Overflow):有2种方法设置V的值:
(1)对于加/减法运算指令,当操作数和运算结果为二进制的补码表示的带符号数时,V=1表示符号位溢出。
(2)对于其他的非加减法运算指令,V的值通常不变。
5. I(Interrupt Request):I=1表示禁止响应irq,I=0表示允许响应
6. F(Fast Interrupt Request):F=1表示禁止响应fiq,F=0表示允许响应
7. T(Thumb):T=0表示当前状态位ARM状态,T=1表示为Thumb状态
8. M4-M0:表示当前处理器的工作模式,如图:
工作模式的切换
(1)执行软中断(SWI)或复位命令(Reset)指令。如果在用户模式下执行SWI指令,CPU就进入管理(Supervisor)模式。当然,在其他模式下执行SWI,也会进入该模式,不过一般操作系统不会这么做,因为除了用户模式属于非特权模式,其他模式都属于特权模式。执行SWI指令一般是为了访问系统资源,而在特权模式下可以访问所有的系统资源。SWI指令一般用来为操作系统提供API接口。
(2)有外部中断发生。如果发生了外部中断,CPU就会进入IRQ或FIQ模式。
(3)CPU执行过程中产生异常。最典型的异常是由于MMU保护所引起的内存访问异常,此时CPU会切换到Abort模式。如果是无效指令,则会进入Undefined模式。
(4)有一种模式是CPU无法自动进入的,这种模式就是System模式,要进入System模式必须由程序员编写指令来实现。要进入System模式只需改变CPSR的模式位为System模式对应的模式位即可。进入System模式一般是为了利用System模式和用户模式下的寄存器相同的特点,因此一般情况下,操作系统在通过SWI进入Supervisor模式后,做一些操作后,就进入System模式。
(5)在任何特权模式下,都可以通过修改CPSR的MODE域来进入其他模式。不过需要注意的是由于修改的CPSR是该模式下的影子CPSR,即SPSR,因此并不是实际的CPSR,所以一般的做法是修改影子CPSR,然后执行一个MOVS指令来恢复执行某个断点并切换到新模式。
转自: 嵌入式资讯精选





首先,我们要分清ARM CPU上的三个地址:虚拟地址(VA,Virtual Address)、变换后的虚拟地址(MVA,Modified Virtual Address)、物理地址(PA,Physical Address)
1.启动MMU后,CPU核对外发出虚拟地址VA,VA被转换为MVA供MMU使用,在这里MVA被转换为PA;最后通过PA读写实际设备
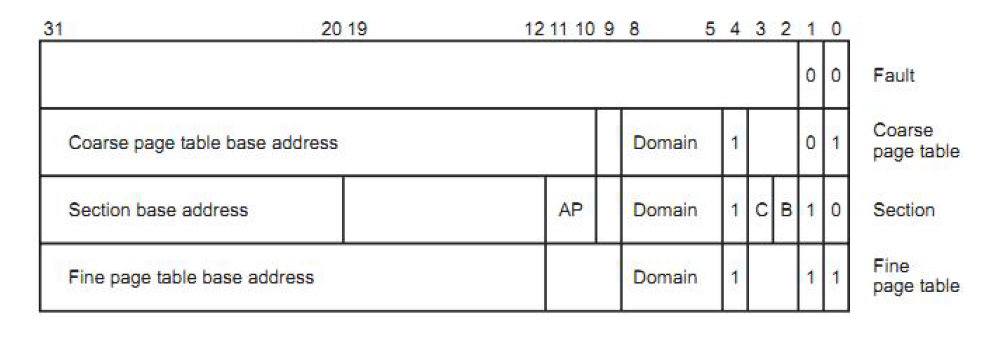
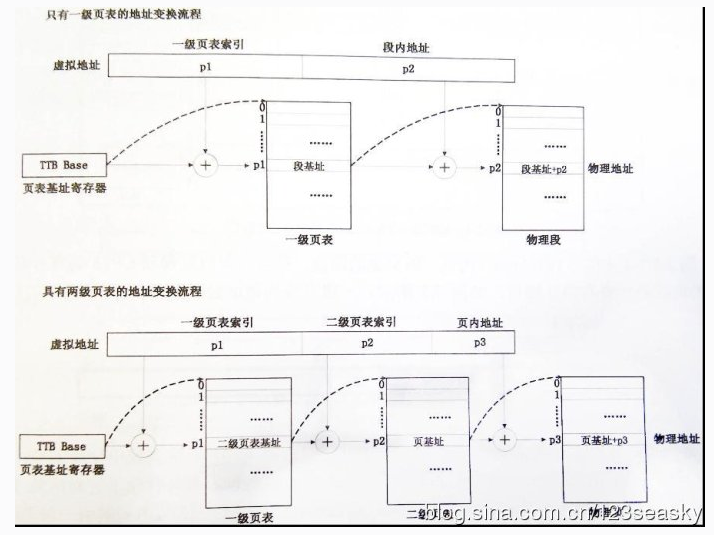
2.MMU的作用就是负责虚拟地址(virtual address)转化成物理地址(physical address)。 32位的CPU的虚拟地址空间达到4GB,在一级页表中使用4096个描述符来表示这4GB的空间,每个描述符代表1M的虚拟地址,要么存储了它的对应物理地址的起始地址,要么存储了下一级页表的地址。使用MVA[31:20]来索引一级页表(4096个描述符)(因为全用MVA的高12位来索引,因此大小为 2^12 = 4096)
3.由协处理器CP15中的寄存器C2(高18位,即[31:14]为转换表基地址,低14位为0)为一级转换表基地址,指向2^14=16KB整除的存储器即16K对齐,这个存储区称为一级转换表;MVA的高12位,即位[31:20]作为一级转换表的地址索引,因此一级转换表具有2^12=4096项,每一项的地址为32位,最高的18位[31:14]为寄存器C2的高18位,中间12位为MVA的高12位[31:20],最低2位为0b00。每一项的内容称为一个描述符,在段(Section)下,一级描述符的高12位为大小为1MB的段基地址,段内地址(偏移地址)为MVA的低20位,即段内每个存储器的地址是这样组成:高12位为一级描述符的高12位,低20位MVA的低20位。这样,借助于寄存器C2和一级描述符,将一个MVA转换成一个PA。(在这里一定要注意:MVA的高12位是用来索引4096个项的,然后使用项的内容(即描述符)的高12位为段的高12位,类似于指针里面存放地址,4096项类似指针,描述符类似指针里面的内容)
4.虚拟地址(注意:是一个确定的地址,不是一个空间)被MMU分成2个部分,第一部分是4096页号索引(descriptor index)即用选择4096(2^12)个号中的某个页号,比喻description index为768,页号768中保存的是物理地址的某个页框的起始地址(0x300),第二部分则是相对于section base(0x300)为起始地址空间为1M的偏移量(offset)(如下图)例如: 假设现在执行指令MOV REG, 0x30100013,虚拟地址的二进制码为00110000 00010000 00000000 00010011,前12位是Descriptor Index = 2^9+2^8+1 = 769,找到769项对应的内容0x301,偏移量为0000 00000000 00010011=13,那么段地址为0x3000000D。
5.地址转换的总体流程:
第一阶段:
(1)从虚拟地址取出前面的31-20位,作为索引。
(2)根据索引在translation table(一级页表)中找到相应的表项。
(3)根据表项最低两位的值决定第二阶段的转换方式。
00:转换无效
01:粗页转换
10:段转换
11:细页转换
(4)linux系统一般用细页转换,也有一定的处理器和操作系统用段转换,很少用粗页转换。。
6.关于TTB(translation table base)
(1)translation table存放在内存中。
(2)由程序员制造,故程序员知道其基地址(TTB)。
(3)程序员将TTB写入cp15的c2寄存器(TTB寄存器)。
(4)MMU工作的时候从c2寄存器去到TTB,从而找到translation table,进而利用虚拟地址的31-20位可以在该表中找到相应的表项,开始虚拟地址到物理地址的转换。。
范例代码:
#define GPKCON (volatile unsigned long*)0xA0008820
#define GPKDAT (volatile unsigned long*)0xA0008824
/*
* 用于段描述符的一些宏定义
*/
#define MMU_FULL_ACCESS (3 << 10) /* 段的访问权限 AP*/
#define MMU_DOMAIN (0 << 5) /* 属于哪个域 */
#define MMU_SPECIAL (1 << 4) /* 必须是1 */
#define MMU_CACHEABLE (1 << 3) /* cacheable 快速访问*/
#define MMU_BUFFERABLE (1 << 2) /* bufferable 缓冲区 */
#define MMU_SECTION (2) /* 表示这是段描述符 */
#define MMU_SECDESC (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_SECTION)
#define MMU_SECDESC_WB (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_CACHEABLE | MMU_BUFFERABLE | MMU_SECTION)
void create_page_table(void)
/*
1. 建立页表
2. 写入TTB (cp15 c2)
3. 使能MMU
*/
{
unsigned long *ttb = (unsigned long *)0x50000000;
unsigned long vaddr, paddr;
vaddr = 0xA0000000;
paddr = 0x7f000000;
*(ttb + (vaddr >> 20)) = (paddr & 0xFFF00000) | MMU_SECDESC;
vaddr = 0x50000000; /* 映射内存 */
paddr = 0x50000000;
while (vaddr < 0x54000000)
{
*(ttb + (vaddr >> 20)) = (paddr & 0xFFF00000) | MMU_SECDESC_WB;
vaddr += 0x100000; /* 每一个表项只能映射1M */
paddr += 0x100000;
}
}
void mmu_init()
{
__asm__(
/*设置TTB 写入cp15的c2中*/
"ldr r0, =0x50000000\n"
"mcr p15, 0, r0, c2, c0, 0\n"
/*不进行权限检查 域的访问权限取决于cp15的c3寄存器*/
"mvn r0, #0\n"
"mcr p15, 0, r0, c3, c0, 0\n"
/*使能MMU*/
"mrc p15, 0, r0, c1, c0, 0\n"
"orr r0, r0, #0x0001\n"
"mcr p15, 0, r0, c1, c0, 0\n"
:
:
);
}
int gboot_main()
{
create_page_table();
mmu_init();
*(GPKCON) = 0x1111;
*(GPKDAT) = 0xe;
return 0;
}转自: __小火车

赛普拉斯超低功耗双核PSoC®6 MCU提供PSA定义的最高级别保护
赛普拉斯半导体公司(纳斯达克代码:CY)近日宣布,推出基于PSoC®6 MCU的支持Arm®平台安全架构(PSA)Trusted Firmware-M的参考实例,是符合PSA标准的最高级别保护能力的解决方案。通过利用PSA全套威胁模型、安全分析、硬件和固件架构规范以及Trusted Firmware-M设计参考,物联网(IoT)设计人员可以快速、轻松地使用PSoC 6 MCU实现安全设计。
Arm物联网设备IP业务部副总裁兼总经理Paul Williamson表示:“互联设备正在快速发展,为了真正实现这些技术所带来的效益,安全性不可忽视。在广大物联网应用中实现安全的MCU开发是业界的共同责任,而赛普拉斯的PSoC 6 MCU将进一步把PSA的优势扩展到我们整个生态系统。”
赛普拉斯微控制器与连接业务部高级副总裁Sudhir Gopalswamy表示:“凭借PSoC 6 MCU的内置安全特性以及与Arm的合作,我们迅速为Trusted Firmware-M提供了支持。我们很高兴能为设计人员提供超低功耗、灵活且符合PSA标准的安全解决方案。”
赛普拉斯PSoC 6 MCU采用双核Arm Cortex®-M内核,与可配置存储器以及外设保护单元相结合,实现PSA定义的最高级别保护。该系列MCU提供三级基于硬件的隔离:1)使用专用Arm Cortex®-M0+内核为可信应用提供隔离的执行环境;2)保护信任操作和系统服务源的安全元件功能;以及3)隔离每个可信应用程序。三个级别的隔离可共同减少威胁的攻击点。该系统增加了一个真正的随机数生成器(TRNG)和加密加速器,而PSoC 6 MCU架构中的Cortex-M4内核则可为不受安全保护的应用程序提供了一个适用于丰富执行环境的清洁编程模型。
根据Arm v8-M的当前版本,PSoC 6 MCU的Trusted Firmware-M参考实例使设计人员能够:
• 通过配置保护单元轻松实现安全和非安全执行环境之间的硬件隔离
• 使用Mbed操作系统安全服务
未来版本将包含多图像可信启动,完整的PSA API支持,以及具有安全元件功能的可信源安装。
供货情况
PSoC 6 MCU Trusted Firmware-M将于2018年3月发布,欢迎早期采用者通过 www.cypress.com/psoc6 注册试用。

