
作者:张国斌
随着算力、算法和大数据日益进步,带动了人工智能技术的迅速普及,目前在人工智能技术应用主要分成两步,首先在GPU等上利用大数据进行训练,优化算法和模型,然后在端侧通过特定的人工智能处理器NPU/APU上实现推理应用,有没有可能同时将训练和推理在一个处理器上实现呢?如果有,这是不是更高效?那将是可以颠覆行业的,也可能实现机器的自我学习和进化呢?
有!Graphcore --一家英国的人工智能领域的独角兽(估值17亿美元),提出了新的IPU(人工智能处理器)架构,它们在2016年10月获得了 3000 万美元A 轮融资(已经累计获得超过3.25亿美元投资),希望其产品可以对抗像英特尔和英伟达这样的人工智能巨头。其投资者包括Dell、微软、Bosch、BMW、Microsoft和Samsung等,它的处理器可以同时支持推理和训练,这可以说是继CPU、GPU、FPGA和ASIC之后的第五类人工智能处理器。

Graphcore的投资主体来自很多大公司
目前,Graphcore的已经量产,主要产品是一款可插入服务器的double-width、full-height 300W PCI Express卡,顶部连接器可以实现卡间互连。每一片Graphcore C2卡都配有两颗Colossus IPU处理器芯片;该芯片本身,即IPU处理器,是迄今为止最复杂的处理器芯片──在16nm单芯片上容纳了240亿个晶体管,每颗芯片可提供125 TFLOPS运算力。以静态影像的前馈卷积神经网络(feed-forward convolutional neural networks)来对比,IPU的性能优势是目前GPU的两到三倍有时甚至是五倍。

Graphcore的IPU产品

全球第一台IPU服务器---Dell DSS8440
Dell DSS8440是第一台Graphcore IPU服务器,具有16个IPU处理器,并在服务器中全部连接了IPU-Link™技术,因此IPU系统具有超过100,000个完全独立的程序,所有程序均在机器智能知识模型上并行工作。
2019年11月14日,Graphcore还宣布与微软进行合作,并发布Microsoft Azure上Graphcore智能处理单元(IPU)的预览版。Graphcore表示,这是公有云领导供应商首次提供GrapchoreIPU,看来未来云计算领域将是Graphcore大展身手的地方,今天我们来聊聊这款人工智能处理器有哪些独特的地方?
独特的架构

Graphcore联合创始人兼CEO Nigel Toon
Graphcore联合创始人兼CEO Nigel Toon去年在接受电子创新网等媒体采访时曾表示对于CPU、GPU、FPGA和ASIC而言,Graphcore的IPU处理器是与它们完全不同的,Graphcore 的IPU特点可概括为:
1、同时支持训练和推理
2、采用同构多核(many-core)架构,有超过1000个独立的处理器;
3、支持 all-to-all的核间通信,采用Bulk Synchronous Parallel的同步计算模型;
4、采用大量片上SRAM,不需要外部DRAM。
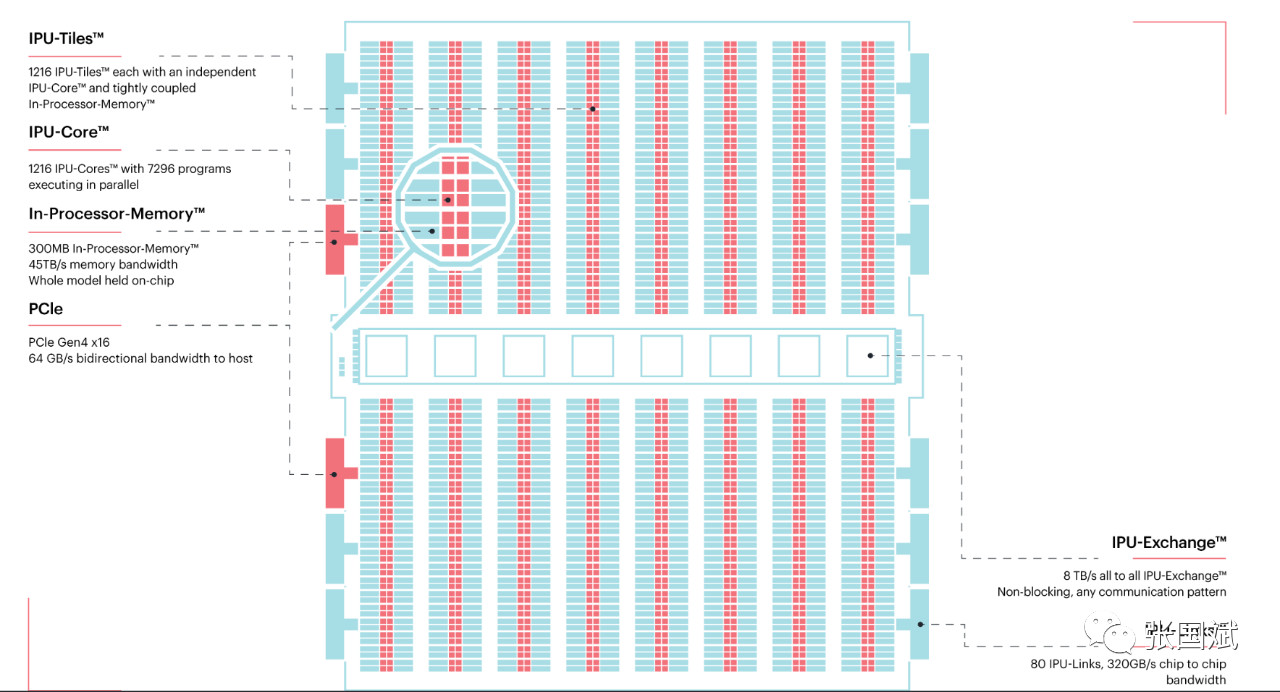
Graphcore的IPU处理器架构
他强调IPU是专门为AI/Machine Learning设计的处理器。Graphcore的IPU有强大并行处理能力,能在自然语言处理以及理解自动驾驶方面取得重大进展,这是区别于其他处理器的一个重要因素。当然,他也顺便喷了一下GPU,
“我们接触过的所有创新者都说使用GPU正在阻碍他们创新。如果仔细看一下他们正在研究的模型类型,你会发现他们主要研究卷积神经网络。因为递归神经网络和其他类型的结构,并不能很好地映射到GPU,加上没有足够良好的硬件平台,其研究领域受到限制。而这正是我们将IPU推向市场的原因。”Nigel Toon指出。
“大家常常对CPU解决不了的问题,试图用FPGA来解决,其实FPGA用的大量场景不在AI领域,而是在网络和存储加速里面。另外,针对AI应用,FPGA无法支持训练,另外易用性差,只可以做一些推理场景。而IPU很明确,专为机器智能或AI应用场景设计,可同时做训练和推理。” Graphcore销售副总裁卢涛补充表示,“IPU是一个处理器,针对IPU我们开发了一套叫做 Poplar 的软件,对程序员来说,在 IPU 上进行开发就是写一个TensorFlow或者Pytorch 的程序,可能就几十行代码,易用性非常好。”
而对于业界认为ASIC方案在场景应用中效能更高的说法,Nigel Toon表示他不认同这个说法,因为不管是什么样的神经网络,不管处理什么应用,最后在底层都会表征成一个计算图,所以IPU设计是来处理计算图的,不管是在处理图片也好,语言也好,最后就是个计算图。所以在我们往后在下一代产品发布的时候,可能会有一些微小的优化,但基本架构还是会维持当前的产品架构,只是处理器的能力强、规模更大,能支持更大的系统,但架构本质上还是当前的架构。
不过Graphcore也表示小型加速器是适合ASIC化的,例如一个拥有大量用户的具有非常特定工作量的公司,或许他们运营着一个庞大的社交网络,他们可以创建一个非常具体的功能并将其构建到一个芯片中,然后将其部署到数据中心以提高这一功能的效率。所以Graphcore不care这个市场,它所做的是一个通用处理器,可以通过编程以惊人的效率来做许多不同的事情。
“在人工智能训练过程中,什么是最重要的?有什么方法可以捕捉到训练数据,并捕捉到这些数据间的关系?让所有数据产生关联,有了足够的数据才能建立出模型。就像小孩子一样,他们的大脑不断地吸收知识,消化知识才能产生知识模型,这些都需要经过长时期才可以建立。有了这样一种模型之后,我们还要有推理引擎,从这些新的知识得到新的输出。其实训练、推理的过程都是一样的,在训练时需要很多计算,而计算需要有足够长的时间,才能让我们的知识得到很好的训练。要培训、要训练这样一个知识模型,就要去监督这些学习过程,才能知道到底从这些数据中学到了什么。我们要建立这样的知识模型是非常复杂的,任何机器的计算模型都可以总结成为计算模式,可以用这些计算模式的描述,来描述这些数据到底是怎么样的,并把这些描述放在神经网络里面,让它们进行学习,然后把知识传输到新的输出上。我们Graphcore的芯片都是高度并行计算,很多种子数据都是同时并行计算的,就像档案里面同时处理很多数据一样。还有很多的并行计算过程正在发生,所以,要用不同的指令、多个机器,让并行计算成为现实。这里的挑战是怎么样确保不同的数据放到合适的地方,在合适的时间进行计算。我们还需要有海量数据带宽来实现高度、大量的数据计算,这就是发明Graphcore IPU的基本思路。”
这是一些对比数据,下图是自然语言处理,Graphcore过BERT语言模型实现了最先进的性能和准确性,在IPU服务器系统中用7张C2 IPU处理器PCIe卡(每个都有两个IPU)在56小时内训练了BERT Base。通过BERT推理,吞吐量提高了3倍,延迟缩短了20%以上。
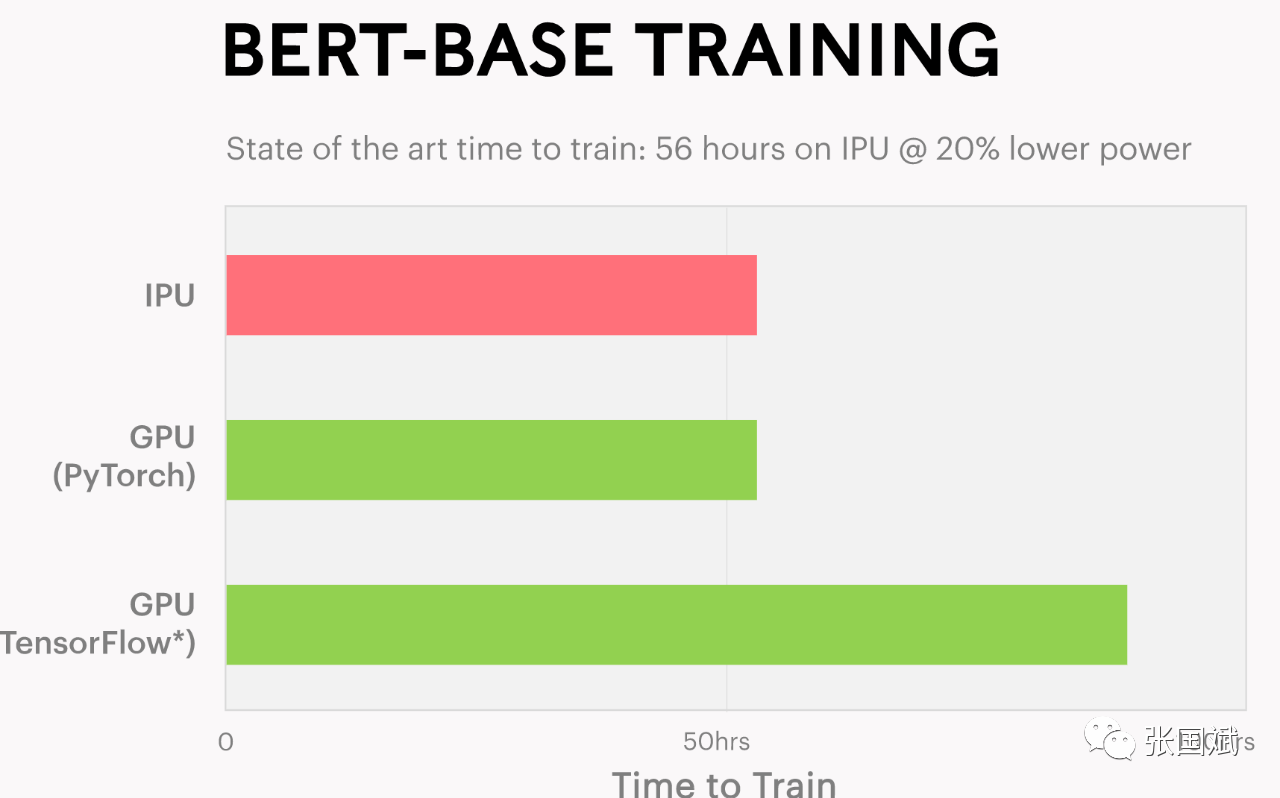
Graphcore IPU自然语言训练对比
与其他领先处理器相比,Graphcore C2 IPU处理器PCIe卡吞吐量提升了3.4倍,延迟优化了20倍!
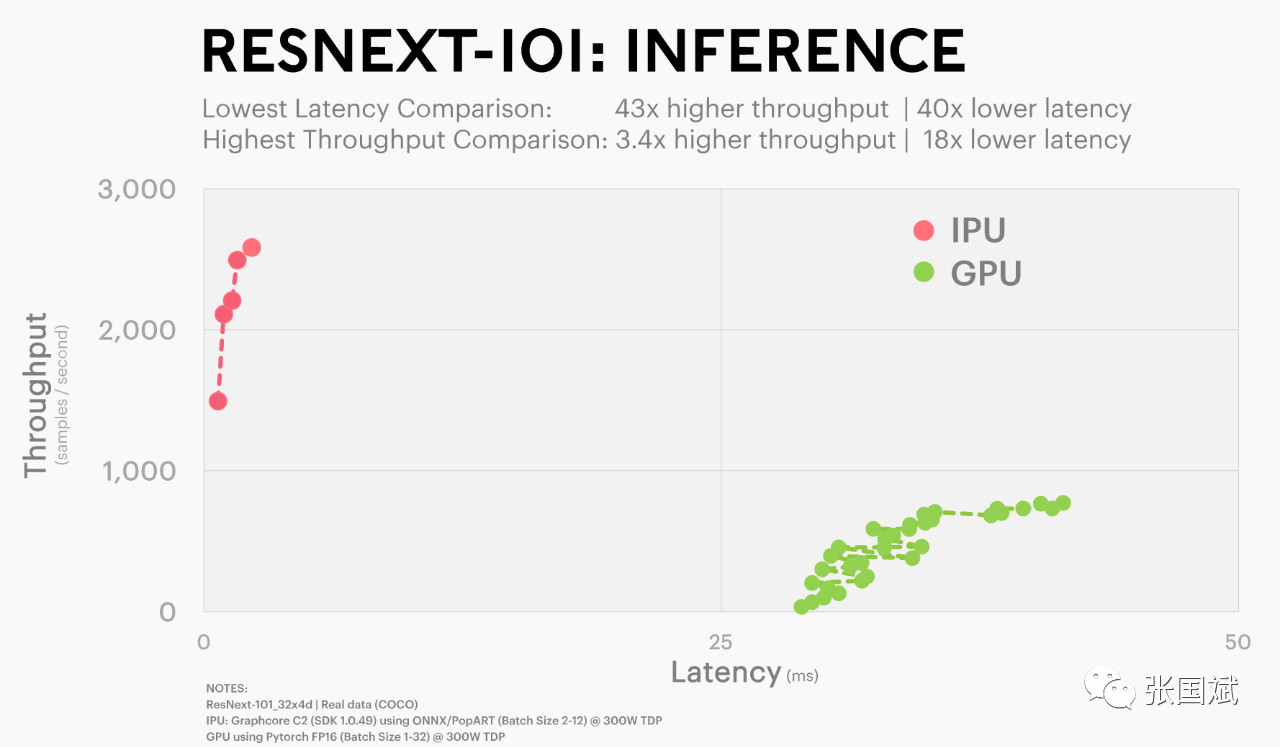
Nigel Toon表示:“Graphcore的IPU 同时有上千个处理器在工作,单个IPU的存储带宽能达到45TB,比性能最快的HBM提升了50倍以上,且在相同算力的基础上能耗降了一半。”
他表示人工智能技术经过简单感知、自然学习的学习处理之后就会到了第三步--就是高度感知,从经验中去学习,要了解到接下来的那一步会发生什么。在自动驾驶汽车里面面临的几大难题就是智能汽车能不能认识到前面的物体,以及它下一步要做什么,在这方面,已经取得了很多进步。这些模型比之前的模型都要复杂,它们高度集成的模型,要把很多东西集成在一起才能做决定。所以,“实际生活中,我们看到的不是单一的知识模型,而是多个知识模型,让它们形成复杂决策过程,这就跟我们的大脑类似,因为我们的大脑可以处理不同的信息。”他强调,“谷歌的智能系统模型正在大规模增长,2016年它只能认识到2500万信息量,2019年2月推出的GPT-2就能处理15亿的参数了,未来还要能处理1万亿的参数,我们需要很大的计算。”他指出,“摩尔定律尽管放缓,但依然有效。我们需要有一种新的处理器,这个新处理器跟过去的CPU和GPU不一样,它是能够产生智能机器的处理器,还可以在同一个处理器同时处理数以千亿的参数,此外还要有能力把不同的IPU系统联系在一起,最后成为一个复杂的系统。而这个处理器要有更加复杂的存储器,能助力更大的机器学习模式,这就是Graphcore的IPU。”
据介绍,借助Graphcore的IPU,一个完整的机器学习模型可以在处理器内部生成。而且IPU处理器具有数百兆字节的RAM,可在处理器上以1.6 GHz的速率全速运行,Nigel Toon说,一个4U机箱中有16个IPU将使用户拥有无可比拟的内存带宽,其上可以运行成千上万的线程,而且同时运行,这是Graphcore得以加速机器智能工作的部分原因。
Nigel Toon表示,Graphcore的IPU相比友商竞品,有三个核心区别:
一是处理器的“核”的架构不同,IPU 是 MIMD 的架构;
二是Graphcore的knowledge model在处理器之内;
三是IPU能解决大规模并行计算处理器核之间的通信效率,这是个非常难的事情。在这一点上,Graphcore有大量的创新,关于多核之间如何通信,如何让软件工程师和程序员处理起来比较简单。
IPU开发复杂吗?
“我们有一个BSP的算法,是硬件和我们的软件一起协同工作的,这样对软件公司来说,虽然处理器有1000多个核,7000多个线程,但是不需要太担心通信问题,可以让软件工程师非常方便地使用,而且处理器核之间的通信效率非常高。”Nigel Toon强调说。
Nigel Toon表示在人工智能领域,框架算法都变化很快,人工智能处理器需要应对灵活性问题,Graphcore的IPU速度会非常快,处理单元可以支撑很多不同的神经网络系统,可以作出新的技术突破,而在这个领域,像今天的CPU或者GPU都难做出技术突破,这些处理器的框架难以需求人工智能领域越来越多的需求。
他表示随着AI的进化,会产生了很多创新的算法,面临的挑战很多,Graphcore和很多知名专家一起合作解决这些挑战,例如Zoubin Ghahramani是剑桥的教授,也是Uber的首席科学家,他发表了很多关于创新算法的论文。他现在也是Graphcore的咨询顾问。另外Graphcore也和AI领域很多知名科学家或者学者合作。

Graphcore销售副总裁卢涛(左)和联合创始人兼CEO Nigel Toon
Graphcore销售副总裁卢涛补充表示,“IPU是一个处理器,针对IPU,Graphcore开发了一套叫做 Poplar 的软件堆栈,对程序员来说,在 IPU 上进行开发就是写一个TensorFlow或者Pytorch 的程序,可能就几十行代码,易用性非常好。”他也表示AI算法发展非常快,核心问题是怎么样能够支持未来的挑战。而IPU是一个处理器,基于这样一个处理器,我们通过软件来实现一些算法,所以它有足够灵活性。“像目前机器学习框架,我们有一套自己的,能够把这个计算图表征成大规模并行计算的一整套库,所以我们觉得很重要的就是,你不能做一个针对当前某一个具体问题,做一个具体的实现,你一定要可编程的。"他强调。“我们在一个芯片里有1200多个处理器核,这里面有一个叫all-to-all exhcange的总线,基本上就是从任何一个核到另外一个核,都可以直接访问,不仅仅是互联,这是第一个维度。 第二个维度,跨到多个芯片时,我们有个IPU-Link协议,可以把多个IPU联结在一起,组成一个集群。all-to-all总线中间的BSP算法,不仅仅是在同一个芯片里面核之间的芯片,跨芯片核之间也可以通过那个协议总线做通信。IPU-Link可以最多支持128个核互联。此外,通过IPU-Link over fabric技术,还能把几千几万颗的处理器连在一起。”

Graphcore的IPU芯片
但这样的强大系统并不意味着就不用对模型做优化了,他表示Graphcore在模型上也做稀疏和剪枝,一般剪枝是要减少参数数量,主要用在推理、部署场景。“有些场景不用做剪枝,因为最后用的是FP16(16位浮点数)来做推理,所以很大程度上剪枝是跟量化在一起的。比如训练一个模型, FP16部署的时候成INT8了,那这时肯定需要做剪枝。
另外,IPU芯片里面有一千多个核,每个核里面都有计算单元和Memory,所以IPU天生就是做稀疏化应用场景性能会更好。
Nigel Toon表示从AI产业的角度来看,AI处理器市场是很大,但目前玩家还是不多,Graphcore的目标是让产品、技术能真正解决行业和客户的问题,然后获得很大的市场。
卢涛表示在AI领域,可编程的处理器虽然目前还只是GPU,但Graphcore认为未来会有更多应用场景,Graphcore要做的是一个非常灵活的处理器,“我们是从0开始,专门针对AI做处理器架构。我们认为未来有很多新型AI应用,我们的IPU会有自己的领域和赛道,并大放异彩。”他强调。
注:本文为原创文章,转载请注明作者及来源