
上一篇文章介绍了 MM32F5 系列 所采用的 “星辰”STAR-MC1 处理器,如果读者还有印象的话,“星辰”处理器相较于 M3 和 M4 处理器的一个主要优势是引入了内存子系统,包括了L1 指令和数据缓存接口和紧耦合 TCM 接口。而仅有内存子系统是不够的,需要配合高效率的总线架构设计来实现其功能最大化。
本期,笔者就来聊聊 MM32F5270 的总线架构设计,看看 F5270 是如何通过高并行度的总线设计实现系统吞吐率的最大化。
MM32F5270 的总线架构
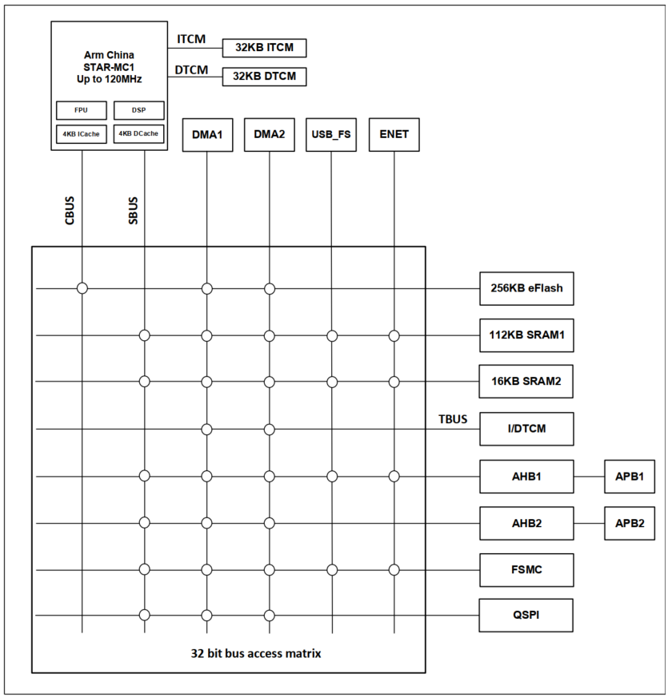
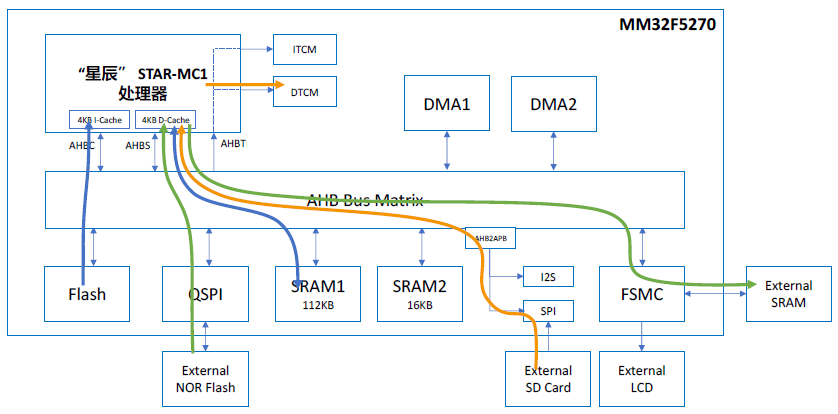
下图展示了 MM32F5270 的总线架构,可以看到,系统中的处理器、存储和外设是通过一个零延迟 AHB 总线矩阵进行互联,这里的总线矩阵是一个多 Master 到多 Slave 的多层 AHB 总线结构。这里,把可发起读写访问的一方叫做 Master,响应访问的一方叫做 Slave。
注:AHB 属于 Arm® AMBA® 通信接口协议的一种,是嵌入式系统中的常用接口协议之一,对于不了解 Arm® AMBA® 接口协议的读者,可自行搜索相关资料,本文不再赘述。
总线 Master – 访问发起者✦
从上图可以看到,MM32F5270 中包含了如下 AHB 总线 Master:
- CPU – “星辰”STAR-MC1
- DMA1
- DMA2
- USB 控制器(USB FS)
- 以太网控制器(ENET)
其中,“星辰”处理器占据 三个 AHB 口,分别是系统总线AHBS(system bus),代码总线 AHBC(code bus),以及 TCM 总线 AHBT(TCM bus)。其中 AHBC 和 AHBS 是处理器发起访问,从外部获取数据和指令的通路,而 AHBT 是处理器以外的其它 Master(如 DMA等)访问内部 TCM 的通路,也就是说,TCM 不仅能被 CPU 访问,外部资源也可以将 TCM 当作普通 SRAM 访问。
其它Master 包括 DMA、USB 和以太网。在 MM32F5270中,为提高系统并行度,配置了两路独立的 DMA 控制器,每个 DMA 控制器包含 8 个通道,每路 DMA 都可以无需 CPU 干预而进行 Slave 的读写访问。USB 和以太网也可以做为总线 Master 直接发起对系统存储的访问,例如将提前放置在 SRAM 中的数据搬移到 TX FIFO 中以实现无需 CPU 干预而进行的数据通信。
总线 Slave – 访问响应者✦
MM32F5270 中包含了如下 AHB 总线 Slave:
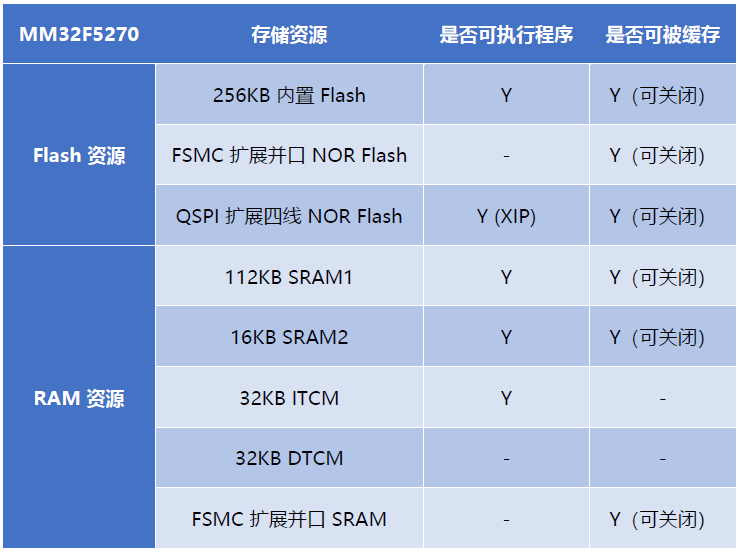
- 256KB 内置 Flash 存储器
- 112KB SRAM1
- 16KB SRAM2
- QSPI – 可外扩四线 NOR Flash
- FSMC – 8/16/32 位并口,可外扩 SRAM,NOR Flash,8080/6800 屏
- 外设 APB1 组
- 外设 APB2 组
- 32KB ITCM和 32KB DTCM – 通过 AHBT 总线访问
为提高系统并行度,MM32F5270配备了两路独立的 RAM,包括 112KB 的 SRAM1 和 16KB 的 SRAM2,每个 RAM有独立的 RAM 控制器和 Slave端口。
此外,MM32F5270 还配备了 32KB 指令 TCM RAM(ITCM)和 32KB 的数据 TCM RAM(DTCM)。这里, TCM 和 CPU 是通过 TCM 接口直连的,相当于一条快速通道,CPU 访问 TCM 不需要经过外部总线矩阵,这也是 TCM 被称为紧耦合存储(Tightly-Coupled Memory,TCM)的原因。CPU 访问 TCM 是没有任何延迟的,因此也不需要经过缓存。同时,“星辰”处理器也预留了 AHBT 总线供 DMA 等 CPU 外部 Master 访问 TCM。这里的 AHBT 总线挂在总线矩阵的 Slave 端,也就是说,DMA 要访问 TCM 需要先经过总线矩阵。当 DMA 和 CPU 同时访问 TCM 时,“星辰”处理器以 CPU 访问为高优先级进行仲裁。需要说明的是,ITCM 支持程序执行和数据读取,其起始地址为 0x0000_0000,DTCM 支持数据读取,其起始地址为 0x2000_0000。
根据上述介绍可以得出,MM32F5270 里实际是配置了 4块完全独立的 RAM,包括 ITCM,DTCM,SRAM1 和 SRAM2,在某些应用场景下,这 4 块 RAM 能够同时被不同的 Master 访问而不会产生任何的总线冲突和等待。例如,CPU 可以读取并执行ITCM中存放的程序算法,以太网可以从 SRAM2 中读写数据,DMA1 可以从 DTCM中搬数据, DMA2 可以从 SRAM1中搬数据,这里的四条通路是完全独立和并行的。
MM32F5270还包含了两路独立的 APB 外设组,即 APB1 和 APB2,每个外设组有独立的 Slave 端口和AHB到 APB 的协议转换桥。
与此同时,用户还可以通过 FSMC 去外扩并口 NOR Flash 或者 SRAM,也可以通过 QSPI 去外扩四线式 NOR Flash。且这里的 FSMC 和 QSPI 都是直接挂在零延迟 AHB 总线矩阵上的 AHB Slave,因此其访问通路是完全独立的。当然,用户也可以通过 SPI、UART等串行总线接口来扩展更多存储空间,不过这些外设都是挂在 APB 总线上,和其它共同挂在 APB 总线的外设共享总线矩阵的 AHB Slave 端口,因此,可能会产生多余的等待周期。
需要说明的是,除了 TCM 和外设空间,从 Code bus 和 System bus 上读取的指令和数据基本上都可以被 4KB 指令缓存和 4KB 数据缓存加速。
下表对 MM32F5270 中支持的 Flash 和 RAM 资源做一个总结:
并发网络✦
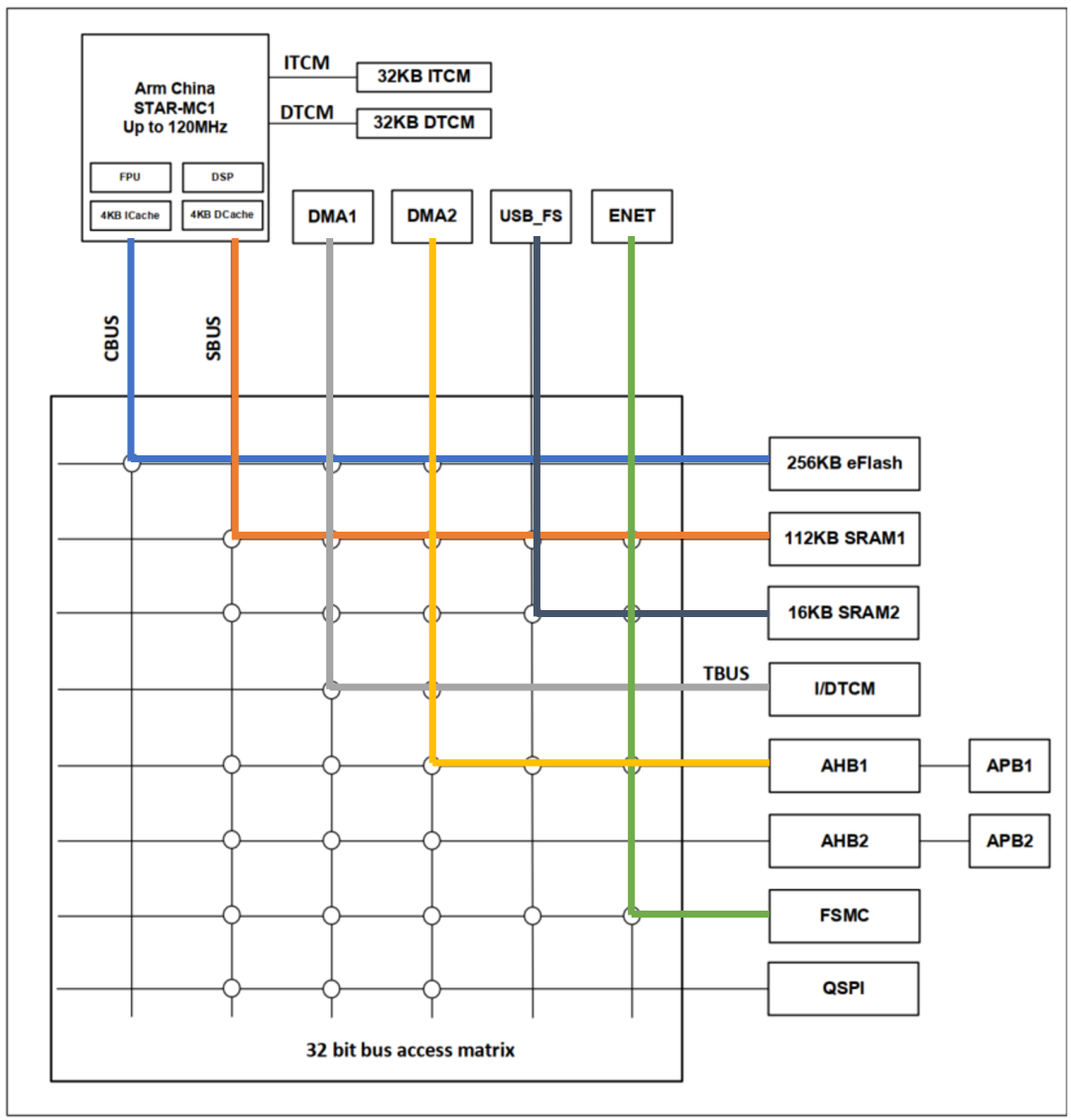
前文提到的总线结构图中,Master 和 Slave 的连接关系通过矩阵网络上的空心圆表示,如内置 Flash 仅可以被 CPU 的 code bus 或者 DMA 访问,而不能被其它总线 Master 访问。
基于上述描述所能达到的效果就是,多个 Master 可以同时发起对多个Slave的访问,如果每条路径的发起者(Master)和响应者(Slave)都是不同的,那这些访问是完全并行的,是不需要仲裁和等待周期的。
下图是一个并发访问的例子,这里,6个总线 Master 对 6 个总线 Slave 的访问构成了 6 个独立通路。当然,这里仅仅是一个极限情况,对于一个实际应用所能达到的并发效果,需要根据应用需求具体分析。
案例:带显示的音频播放器✦
为了更直观的讲解 F5270 多并发总线设计的强大,这里以一个实际应用的案例来进行展示。需要说明的是,这里的案例仅仅为了讲解功能,并不做为参考设计。
这里,考虑基于 MM32F5270 制作一个带显示的音频播放器,这是一种很常见的应用场景,实际产品中所包含的功能可能是多种多样的,这里为了简化,以如下规格要求为例:
- 可播放 SD 卡上的音频文件,支持 WAV 和 MP3 格式
- 2.4寸屏,320x240 分辨率,GUI 交互
注:实际的产品可能有更多的功能,如更高清的显示、USB扩展、WIFI 或蓝牙联网、视频播放、触控等,感兴趣的读者可以搜索下网络上的相关产品。
基于这个要求,可以搭建一个带显示的音频播放器,根据 MM32F5270 所包含的片内资源,对上述规格要求做出如下的功能分解和资源分配:
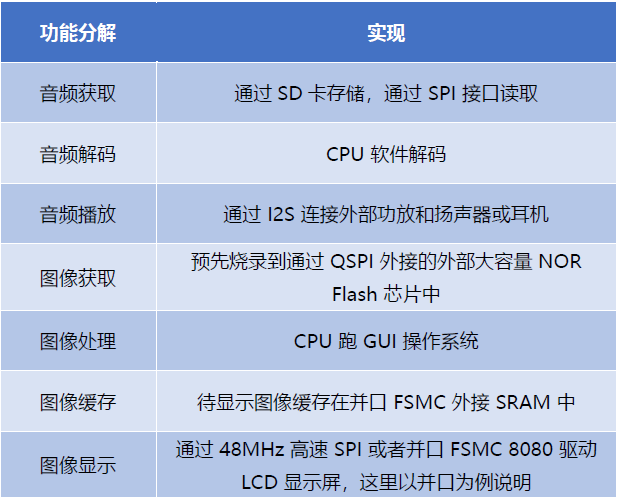
其对应的简易系统框图如下:

分析可知系统的主要功能可以分为三块:
第一块是 CPU 处理部分。
首先, CPU 所执行的主程序存放在内置 256KB Flash 中,而运行中所需要内存存放在 SRAM1 中,其数据通路如下图中的蓝色箭头所示;
同时,CPU 需要从外部 SD 卡读取音频文件,这里涉及到文件系统的交互,以及 MP3 软解码运算,并将解码后的音频数据存放在 32KB DTCM 中,其数据通路如下图中的黄色箭头所示;
最后,CPU 需要运行 GUI 应用程序,包括从外扩 Flash 中获取显示数据和字库,通过 CPU 的运算并将待显示的图像缓存到外扩 SRAM 中,其数据通路如下图中的绿色箭头所示。
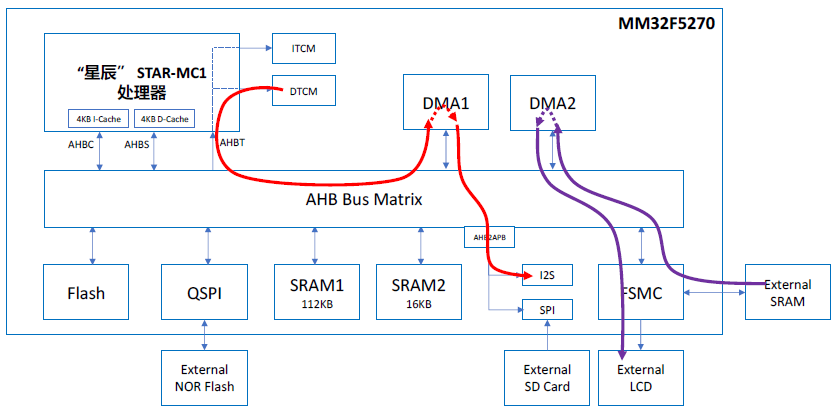
第二块是音频播放数据流控制。
这里,通过 DMA1 来处理音频数据流,DMA1 通过 AHBT 总线从 DTCM 中读取解码后的音频数据,并写入 I2S 的 TX FIFO 中,通过 I2S 和外部的功放通信并驱动扬声器或耳机,其数据通路如下图中的红色箭头所示。
第三块是图像显示数据流控制。
这里,通过 DMA2 来处理图像显示数据流,DMA2 通过 FSMC 从外部 SRAM 中读取待显示图像,并通过 FSMC 写入外部 LCD 屏,实现图像帧的周期性刷新,其数据通路如下图的紫色箭头所示。
基于上述分析,将所有路径进行汇总,并删掉非独立路径后(即两条路径有共同发起者或共同接收者),可得到下图所示的汇总数据通路。可以看到,主程序的指令获取和执行(蓝色箭头)、主程序数据读写(蓝色箭头)、音频数据流(红色箭头)和GUI数据流(紫色箭头)这四条通路是完全独立的。假设系统运行在 120MHz,而所有访问都采用 32 位宽,则可以计算出此时整个系统的并行吞吐率可达 15Gbps!
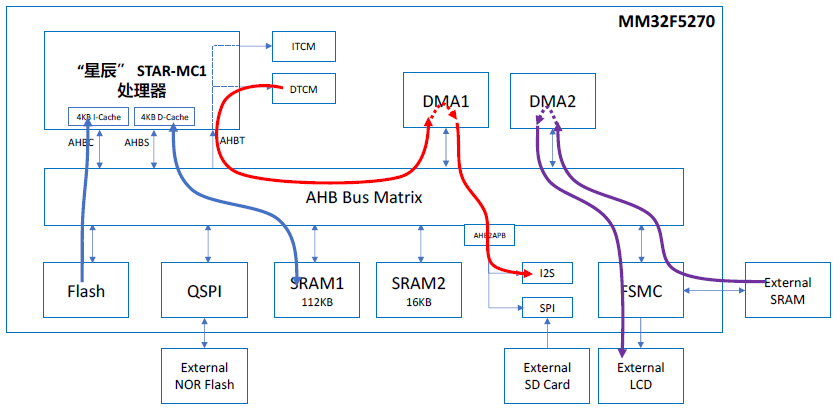
当然,这里仅仅是一个精简的例子,对于实际应用,其所需功能可能会更加复杂。但重要的是,MM32F5270 的多并发总线架构为各类实际应用中的并行处理场景提供了硬件支持,使系统整体吞吐率有了大幅优化的空间。
需要补充说明的是,这个例子里面并没有用到 SRAM2 和 ITCM 等资源,因此其可以用作其他用途,如 SRAM2 可以用作 ENET、USB 、CAN 或者 ADC的数据缓存,而ITCM 中可以存放对实时性要求较高的算法或中断服务程序等。如果把这些功能都开发起来,则系统吞吐率是否还可以进一步提高呢?这个问题就留给感兴趣的读者来思考吧。
小结 & NEXT✦
本文介绍了MM32F5270 中所采用的多并发总线架构,并通过带显示的音频播放器的实例说明了该架构在实际应用中所能达到的吞吐率提升效果。
未完待续!本文是 MM32F5 漫谈系列的第二篇,后续将为大家持续更新,旨在分享 MM32F5 系列中所包含的那些有趣的技术,敬请期待!
往期回顾
来源:电子创新网张国斌
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。