
目 录
“星辰”处理器是什么?
看似很厉害,跑个分?
C 代码兼容 M3 和 M4
完善的生态支持
小结 & Next
近期,灵动微电子发布了灵动“星”平台,其全新高性能 MM32F5 微控制器系列。该系列在内核、总线和外设配置等多个方面进行了创新,内核上更是首次搭载了 Armv8-M 架构的 “星辰” STAR-MC1 处理器,因此一经发布就获得了大量用户和媒体的关注。
很多用户会咨询“星辰”处理器相关的问题,特别是“星辰”处理器是什么样的内核?相较于 Arm Cortex-M 系列内核又有什么差别?这里,为了让大家对“星辰”处理器有一个快速的了解,并解答上述的这些问题,本文对“星辰”处理器的主要特色做一个梳理。

“星辰”处理器是什么?
如果用一句话介绍“星辰”处理器,那就是:安谋科技设计的一款基于 Armv8-M 架构的嵌入式处理器。这里,安谋科技是中国最大的芯片设计 IP 开发与服务供应商,而灵动微电子则是从安谋科技获得了该处理器的正规使用授权,并于 MM32F5 系列中首次搭载了该处理器。
“星辰”处理器的几大特点如下:
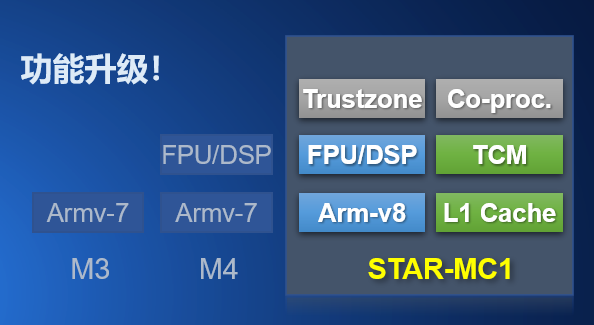
采用最先进的Armv8-M架构
处理器是基于指令集架构设计实现的运算和控制单元,而 Arm 处理器的指令集架构自诞生以来也在不断的更新换代,目前市面上较为常见的 Arm MCU 架构包括 Armv6-M、Armv7-M和 Armv8-M 架构,其中,Armv6-M 架构的典型处理器有 Cortex-M0 和 Cortex-M0+,Armv7-M 架构的典型处理器有 Cortex-M3、Cortex-M4 和 Cortex-M7,而 Armv8-M 架构的典型处理器则有 Cortex-M23、Cortex-M33、Cortex-M55 和 “星辰”STAR-MC1。
经常关注 MCU 前沿动态的话一定会有所了解,近几年来国际上最主要的几家 MCU 大厂的新产品已经逐渐从 Armv7-M 架构过度到了 Armv8-M 架构,如ST、NXP、Renesas等。那么 Armv8-M 架构相较于 Armv7-M 架构,究竟有哪些优势?
性能提升
Armv8-M 架构优化了指令集和流水线设计,其同级别产品的性能相较于 Armv7-M架构普遍提高20% 以上。
更安全
Armv8-M 架构引入了 TrustZone 技术,并强化了内存保护单元(MPU),让代码运行在更安全的环境中。
可扩展
Armv8-M 架构引入了协处理器接口,允许 MCU 产商自己开发协处理器和自定义指令,相较于传统的基于地址映射和中断的协处理器可大幅提升执行效率。特别是Armv8.1-M架构,还预留了用户自定义指令的接口。
集成 DSP 和 FPU
弥补了 Cortex-M3 的短板,DSP 性能相较于 Cortex-M3 提升10倍。
集成内存子系统
在计算机体系结构中,除了处理器内核的设计外(指令集、流水线、ALU等等),存储架构的设计也是重要的一环。在特定应用场景下,高效率的存储访问对系统整体性能所带来的提升效果可能比提高内核性能本身还要来得明显。而提升存储访问效率的方法往往有两个:
层次化设计(Memory Hierarchy)
层次化设计的核心是缓存(Cache)。在嵌入式系统中,处理器运行速度远快于 Flash 的运行速度(典型值是 2:1 到16:1), 而处理器要从 Flash 中获取执行代码,如果 Flash 速度不做优化的话,可以说处理器跑的再快也会受到 Flash 读取速度瓶颈的制约。而最有效的解决方法就是在处理器和 Flash 之间加入缓存,这里的缓存可能是多层的,一般把靠近处理器一端的缓存叫做一级缓存(Level 1或简写为 L1),而靠近 Flash 一端的缓存叫做二级缓存(Level 2 或简写为 L2),一般情况下,因 L2 缓存和 CPU 之间还间隔了一个总线矩阵,因此 L1 缓存的效率往往高于 L2 缓存。
增加并行访问路径提高吞吐率
一般而言,越高性能的内核,其并行访问通路越多,多条通路可并发访问,因此系统吞吐率可以成倍增长。如Cortex-M0 和 Cortex-M0+ 仅有一条系统总线,指令和数据均通过一条总线访问;Cortex-M3 和 M4 中将指令和数据进行了区分,可以在取指的同时获取数据;Cortex-M7 则进一步引入了指令紧耦合 RAM (以下简称 ITCM)总线和数据紧耦合 RAM(以下简称 DTCM)总线,以及引入了独立外设总线(AHBP)。
而“星辰“ 处理器所集成的内存子系统同时采用了上述的两种技术。
首先,“星辰”处理器配置了 L1 指令和数据缓存,该缓存和内存紧耦合,可以用来加速任何指令和数据总线上的访问,这里包括内置 Flash 和 SRAM中的指令和数据,以及外置 Flash 、TF 卡、外置 RAM的指令和数据等。
同时,“星辰”处理器也引入了独立的 ITCM 接口和 DTCM 接口,用于访问与处理器紧耦合的指令和数据 RAM,处理器对于 TCM 的访问完全可以和指令和数据总线的访问并行执行。而且,当 CPU 不访问 TCM 时,TCM 也可以被 DMA 等外设通过独立的 TCM总线(AHBT)访问。
在 Armv7-M 架构处理器中,内存子系统仅在最高性能的 Cortex-M7 上才有配置。“星辰”处理器配备上内存子系统可以大幅提高系统吞吐率。
本土团队打造
在目前的国际形势下,国外对出口到我国的关键技术的管制风险一直没有缓解,而不断出现的国际纷争更是加剧了这种风险的可能性。如何应对随时可能加码的出口管制风险,做到在核心技术上不被“卡脖子”,关乎国产半导体的命脉,是所有国内半导体人需要共同面对和思考的问题。
“打铁还需自身硬”,应对出口管制和贸易战的风险,打造完全自主可控的本土半导体供应链是必要的。而据安谋科技介绍,“星辰”STAR-MC1 处理器由安谋科技本土团队设计打造,本土技术的占比高于90%,因此,真正意义上做到了自主可控。
总结而言,“星辰”STAR-MC1 处理器是一款采用了先进架构、优化了总线和存储配置、且完全自主可控的高性能处理器。
看似很厉害,跑个分?
基于上述的介绍, 大家可能还是没办法直观的感受到 “星辰”处理器的强大,那下面就以国际通用的 CoreMark 跑分结果来进行说明。
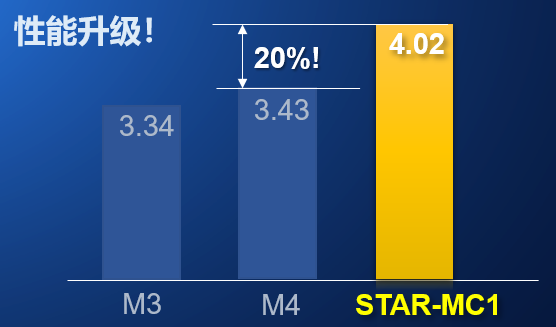
下图列举了 “星辰”STAR-MC1 处理器的标称 CoreMark 跑分和同级别 Cortex-M 内核的比较。可以看到,STAR-MC1的跑分为 4.02 CoreMark/MHz,其相较于 Cortex-M3 提升了 20%,相较于 Cortex-M4 提升了 17%。因此,从核心性能而言,STAR-MC1 是一款介于 Cortex-M4 到 Cortex-M7 之间的处理器。
需要说明的是,这里的跑分数值是各处理器的理论极限值,该理论极限值一般可通过把 CoreMark 代码放在零延迟 RAM 中执行而获得。而在实际应用中,用户的程序往往是从 Flash 中执行,如果存储层次设计不好,其所获得的 CoreMark 跑分结果将大打折扣。
而得益于 STAR-MC1 出色的内存子系统设计,保证了其 Flash 跑分结果和理论极限值几乎没有差别。
根据 MM32F5270 芯片上的实际测试结果,当 L1 缓存打开时,从Flash 中执行 CoreMark 的跑分结果是 3.97 CoreMark/MHz,该数值达到了理论极限值的 99%。因此,当用户在 Flash 中执行程序的时候,依然可以获得相较于 Cortex-M3 和 Cortex-M4 的理论极限值约 20% 的性能提升。
同样因为 STAR-MC1 出色的内存子系统设计,在 Flash 执行代码的前提下,搭载 STAR-MC1 并开启了内存子系统的 MM32F5 系列相较于搭载了 Cortex-M3 或 Cortex-M4 的芯片而言,能够更接近其理论极限值。因此,如果以 Flash 中实际运行的结果来对比 STAR-MC1 和市面上的 Cortex-M3 和 Cortex-M4 芯片,STAR-MC1 将带来 30%~50% 的性能提升。
C代码兼容M3和M4
综合以上 “星辰” STAR-MC1 处理器的介绍,可以说 STAR-MC1 是 Cortex-M3 和 Cortex-M4 的理想升级选择。
那么,假如用户从上述 Armv7-M 处理器切换到 Armv8-M 架构的 STAR-MC1 处理器时,是否很难移植呢?当然不是!
STAR-MC1 和 Cortex-M3 和 Cortex-M4 都是基于 Arm指令集架构的处理器,因此,其兼容性还是很高的,但由于底层指令集架构由 Armv7-M 过渡到了 Armv8-M ,因此,其无法做到完全的二进制兼容,但STAR-MC1 实现了从 Cortex-M3 和 Cortex-M4 移植时的 C 代码兼容。因此,假如用户的代码是基于 C 语言编写,则完全不用担心兼容性。
完善的生态支持
很多用户会咨询 STAR-MC1 的工具支持状况、是否支持 KEIL等问题。这个大家也可以完全放心,STAR-MC1 作为一款通用的嵌入式处理器,其目前已经获得了非常完整的生态体系支持。
下图列举了 STAR-MC1 截止目前的生态工具支持情况,可以看到,STAR-MC1 在工具链、编译器、操作系统和仿真器方面都获得了主流工具的支持:
工具链
在工具链方面,STAR-MC1 已经获得了 Arm DS、Keil、IAR、SEGGER Embedded Studio、Lauterbach TRACE32 等主流 IDE 的支持。
编译器
在编译器方面,STAR-MC1 已经获得了 GCC、Arm Compiler、IAR Compiler、SEGGER Compiler 等主流编译器的支持。
仿真器
在仿真器方面,STAR-MC1 已经获得了 ULINKPRO、ULINK2、DSTEAM、SEGGER J-Link Base/Plus、J-Link Ultra/Pro 的支持。
操作系统
在操作系统方面,STAR-MC1 更是已经获得了 MbedOS、freeRTOS、Zephyr、OpenHarmony 的支持。

小结 & Next
“星辰”STAR-MC1 处理器是一款 Armv8-M 架构的高性能嵌入式处理器,由安谋科技本土团队打造,集成了出色的内存子系统,并获得了完整的生态支持,是升级 Cortex-M3 和 Cortex-M4 内核的理想选择!
未完待续!本文是 MM32F5 漫谈系列的开篇,后续将为大家持续更新,旨在分享 MM32F5 系列中所包含的那些有趣的技术,敬请期待!
来源: 灵动MM32MCU
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。