
来源: http://www.tuicool.com/articles/YJfqUjV
最近在利用空余时间写一个兼容MIPS32指令集架构的CPU,尽管它和Intel的不同,但MIPS对nop指令的处理方式可以给你一点启发。
首先上过计算机体系结构课的你一定知道,现代CPU都采用流水线结构。在一个简单的五级流水的MIPS32处理器中,五级流水分别实现的逻辑操作是: 取指、译码、执行、访存、回写 。
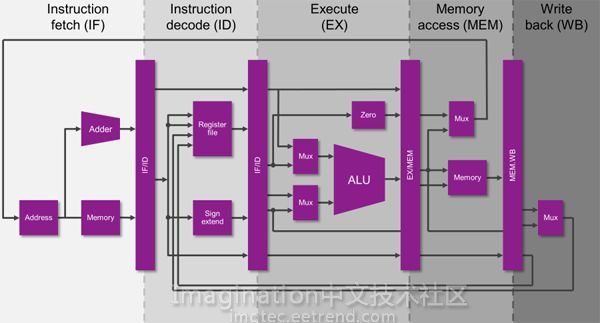
(图片来自网络,侵删)
在取指阶段,cpu从内存中代码区读取指令,然后将其送入译码阶段进行译码。那么译码阶段做了什么呢?要了解这一点,我们先来看看指令本身长什么样子,以移位操作指令sll为例,其在汇编语言中的用法为:
sll rd, rt, sa
意思是将地址为rt的通用寄存器的值向左移sa位(空出来的位置用0填充),得到的结果保存到地址为rd的通用寄存器中。(寄存器在上面那张图中就是译码阶段上方的那个“Register file”方块)
这么一条汇编指令用32位二进制表达将会是这个样子:

译码阶段先通过前六位和后六位识别出它是SLL移位指令,然后从rt寄存器读取数据,将其与“sa”一起送入执行阶段,并且告诉执行阶段: “数据已经给你了,请利用这两个数据做移位操作,做完请保存在rd这个地址。”
这下清楚了,译码其实就是在识别、拆解指令码,并准备好数据(这个数据可能来自寄存器,也可能就来自指令)送给执行阶段去执行特定的计算。至于访存和回写在干什么,与此问题无关,就不做介绍了。
有意思的来了。 我们来看看nop指令长什么样吧:

没错, 全0 。这就有问题了,按照刚才SLL指令的说明,SLL指令是通过前六位和后六位唯一确定的,那么nop指令被送往译码阶段后,不就会被当成SLL指令么……你别说,还真是。
按照sll指令的译码和执行方案,nop指令会被解释成这样:
sll $0, $0, 0
意思是把地址为$0的寄存器的值拿出来,左移0位,再存到地址为$0的寄存器当中去……那么寄存器$0里保存着的是什么呢…… MIPS32架构规定$0的值只能为0。
所以nop指令被CPU当成sll指令做了一次无意义的移位操作,实际上等于什么都没做,只是占用了一级流水线,如@龚黎明大大所说,用来作流水线填充,白白占用1个T的等待时间。