实战经验 | 如何修改STM32Cube固件包的存储位置


本文是基于一个客户的问题,讲述了如何将STM32Cube固件包的位置移动到其他位 置,用来节省C盘空间。
本文是基于一个客户的问题,讲述了如何将STM32Cube固件包的位置移动到其他位 置,用来节省C盘空间。
意法半导体推出新软件包STM32CubeMP13来帮助工程师把STM32微控制器应用代码移植到性能更强大的STM32MP1微处理器上,将嵌入式系统设计性能提高到一个新的水平。
STM32今年推出的新产品STM32H5除了兼具性能、功耗与集成度的优势外还进一步提升了产品的安全特性,在信息安全保护方面带来了很多新的特性以及创新的解决方案。

STM32助力开发者释放创造力,推出STM32开发者优先计划,软件下载量和硬件发货量均大幅提升,通过国内社交平台和ST中国大学计划获得电子行业从业人员对STM32的认可。

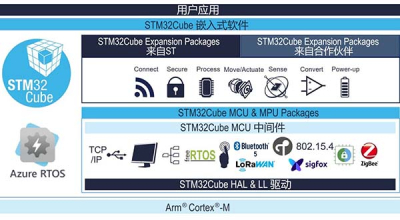
STM32CubeU5 MCU 包带一组丰富的运行于意法半导体板件之上的示例。示例按板件进行管理,提供预先配置的项目给主要支持的工具链(请参考)。

意法半导体(ST)发布了STM32Cube.AI version 7.2.0,这是微控制器厂商推出的首款支持超高效深度量化神经网络的人工智能(AI)开发工具。

今天我们将展示如何自行训练机器学习模型,然后使用STM32Cube.AI 将其部署到同一设备上,以便让大家充分了解两种工具的不同之处。

STM32的标准外设库、HAL、LL软件库,都有很多巧妙之处值得大家借鉴。今天讲讲STM32Cbue LL库中巧妙运用“静态内联”使代码更高效。

STM32Cube.AI是意法半导体AI生态系统的一部分,是STM32Cube的一个扩展包,它可以自动转换和优化预先训练的神经网络模型并将生成的优化库集成到用户项目中,从而扩展了STM32CubeMX的功能。

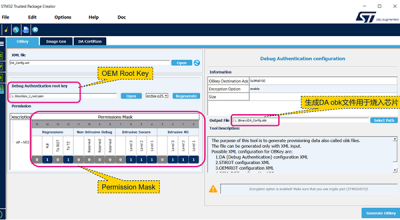
在该应用笔记中,使用IAR™EWARM IDE作为示例,为项目配置提供指南。安全启动和安全固件更新应用程序被称为SBSFU。