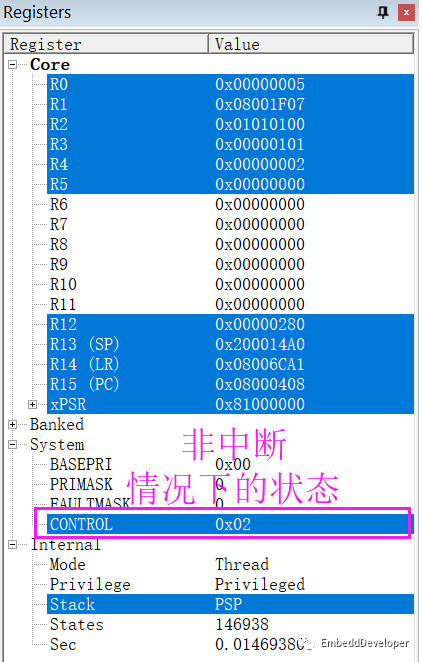
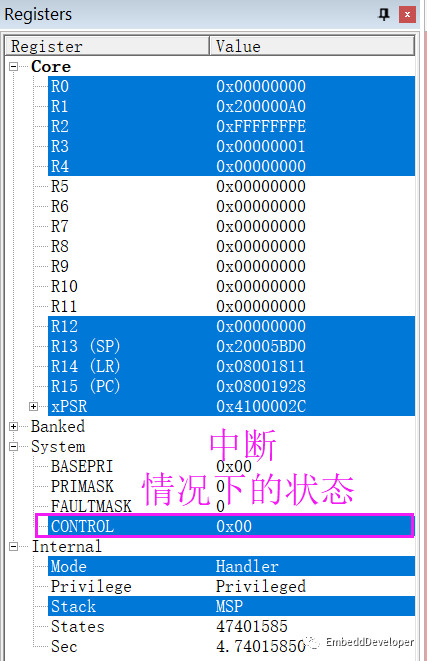
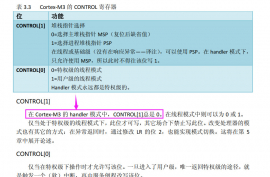
如果CPU没有中断,你能想象是什么情况吗?
就是一个while循环,且不能中断处理及时的任务,更别说有现在的RTOS了(RTOS也是需要中断才能实现)。
下面就来说说关于Cortex-M中断在RTOS应用及注意事项。
关于Cortex-M处理器
这里先介绍一点Cortex-M处理器相关的内容,本文结合内核为Cortex-M3的STM32来讲述。
STM32属于ARM中Cortex-M系列处理器,比如:STM32F1数据Cortex-M3,STM32F7数据Cortex-M7。

可以参看我之前分享文章《从Cortex-M到Cortex-A认识ARM处理器》,了解一下关于ARM处理器的种类。
本文主要结合Cortex-M3下面STM32F1系列处理器为例来讲述中断控制相关内容。而Cortex-M其它系列,或者说STM32其它系列关于中断的内容类似。
Cortex-M3只是STM32F1的一个内核。反过来说STM32F1是在Cortex-M3基础上增加了一些外设(如:USART、AD等)的芯片。
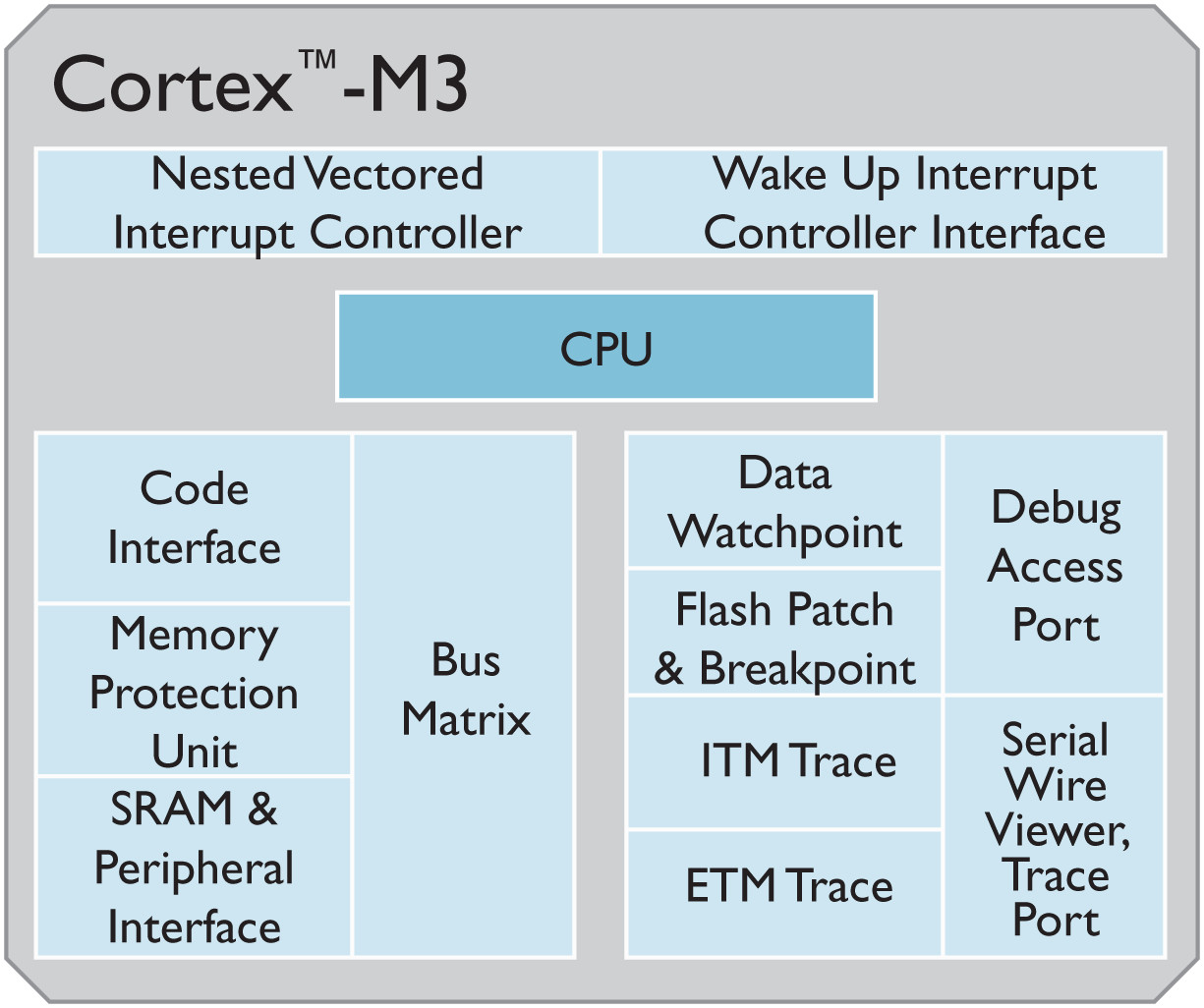
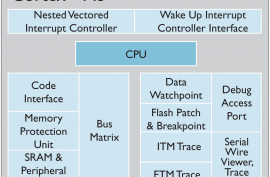
Cortex-M中断控制
NVIC:Nested Vectored Interrupt Controller,即嵌套向量中断控制器。
STM32中NVIC我们比较熟悉,编程的时候使用中断都会对NVIC进行配置。
而STM32F1中的NVIC是属于Cortex-M3中的一部分,而不是STM32增加的外设。
NVIC向量中断控制器是Cortex‐M3不可分离的一部分,它与 CM3 内核的逻辑紧密耦合,有一部分甚至水乳交融在一起。
所以,NVIC相关的寄存器位于Cortex-M手册中。讲述STM32的中断控制,还得从Cortex-M3的NVIC讲起,
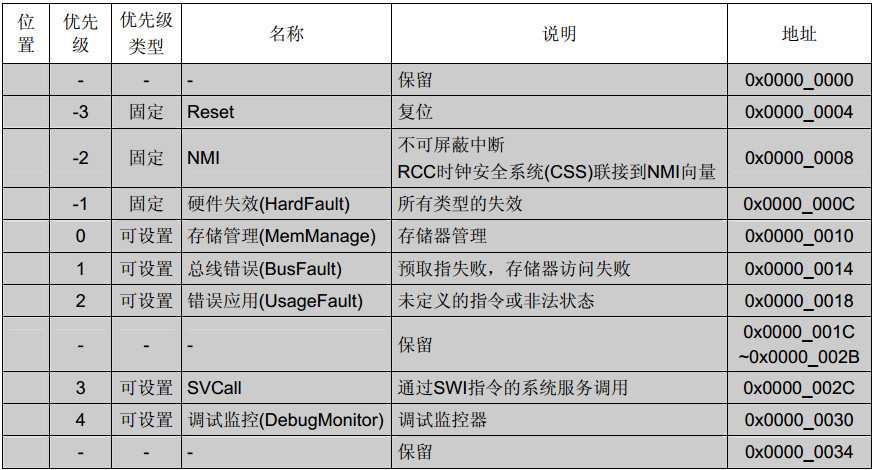
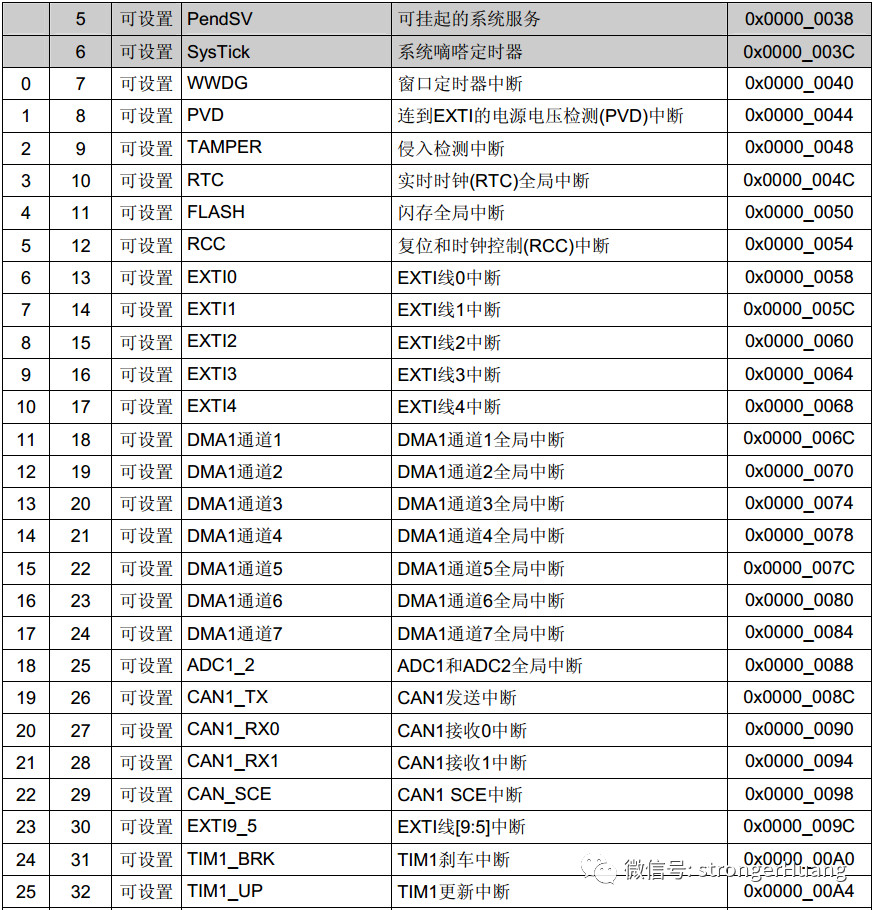
1.中断输入向量表
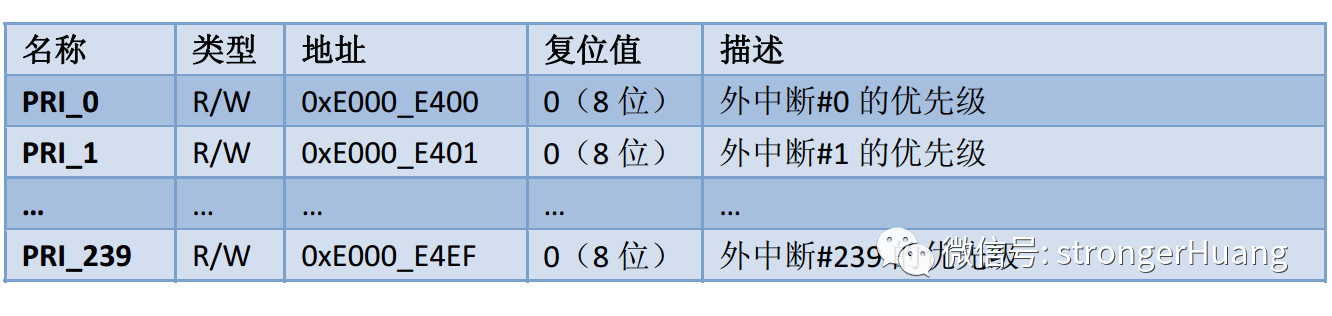
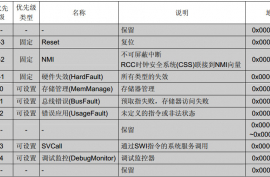
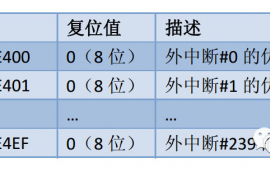
Cortex-M3的NVIC支持1至240个中断输入,比如STM32中xxxIRQs,也就是中断向量表,具体的数值由芯片厂商在设计芯片时决定。
比如STM32F1的中断和异常向量表:


2.中断和异常区别很多初学的朋友不知道什么是中断?什么是异常?甚至有人直接把中断和异常笼统称为“中断”。
中断和异常其实有差异,也有关联,我们常说的中断其实是包含了异常。异常可以理解为MCU,或者程序处于了某种异常状态。
这么区分吧,看上面向量表,上部分有灰色背景的为异常,下部分白色的为中断。
异常属于Cortex‐M3内核的一部分,而中断属于MCU(STM32)的一部分(由厂家决定)。
所以:1.站在Cortex‐M3内核角度,像STM32中USART这类中断,属于外部中断。
2.站在STM32角度,EXTI外部引脚中断才属于中断。
3.优先级对于Cortex-M3来说,每个外部中断都有一个对应的优先级寄存器。
每个寄存器占用8位,但是允许最少只使用最高3位,在STM32F1中使用了高4位。(也就是我们可以分16个优先级)
优先级可以被分为高低两个位段,分别是抢占优先级和亚(响应)优先级。

提示:
1.STM32中断优先级数值越小,优先级越大。
2.优先级分组:Cortex-M3,M4具有分组功能,即存在抢占优先级和响应优先级,如下图:

而有的内核就没有,如Cortex-M0就没有。
3.参考资料
可以参看《Cortex-M3权威指南》
STM32的内核编程手册:http://www.st.com/stonline/products/literature/pm/15491.pdf
RTOS中断优先级配置
本节内容讲述一下FreeRTOS最大中断优先级配置问题,也就是FreeRTOSConfig.h配置文件中的:
configMAX_SYSCALL_INTERRUPT_PRIORITY

你们知道配置数值的含义吗?这里就需要结合NVIC相关的内容来理解。
上面说了,在STM32中,使用了NVIC优先级的高4位,而我们配置时需要对高4位进行配置(低4位未使用)。

看上图,明白了吗,上面这个数值就是95,但代表的优先级为5。
这个配置数值的含义,大概意思是:你代码中使用的中断(比如USART1_IRQn)优先级需要大于5才可行。
如下面配置,优先级为2就不行(当然,有分组的还牵涉到分组问题)。

关于FreeRTOS最大优先级配置的内容可以参考:https://www.freertos.org/RTOS-Cortex-M3-M4.html
最后再次提示:FreeRTOS任务优先级是数值越大,优先级越高,需要和CM3中断优先级区分开来。
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。