01、应用需求
STM32G4由于其出色的外设以及中高性能的内核,得到了越来越多的客户认可,成功地应用到了工业、电机控制、数字电源等领域。在开发过程中,如何提升STM32G4的运行及计算性能成为越来越多工程师们开发过程中遇到的问题。本文结合文档以及实际测试提出来一些改进措施。
02、改进性能方法
2.1. 对编译器设置合理的优化等级
Arm®嵌入式编译器执行多种优化,以减少代码大小并提升应用程序性能。不同的优化等级针对不同的优化目标。因此,针对某一目标进行优化会影响其他目标。优化等级总是在这些不同目标之间进行权衡。
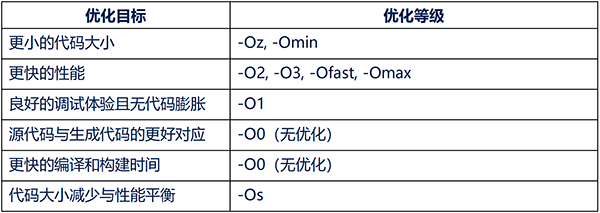
Arm®嵌入式编译器提供多种优化等级,以控制不同的优化目标。最佳的优化等级取决于具体的应用程序和优化目标。
2.2. 加速对FLASH的访问
Adaptive real-time memory Accelerator (ART Accelerator)针对STM32的Arm® Cortex®-M4处理器进行了优化,它平衡了Arm® Cortex®-M4处理器与FLASH技术之间固有的性能优势,通常FLASH需要处理器在较高工作频率下等待对FLASH访问。
为了释放处理器的全部性能,ART Accelerator实现了指令预取、队列和分支缓存,从而提升对FLASH的程序执行速度。
Cortex®-M4通过ICode总线获取指令,通过DCode总线获取常量/数据。Prefetch块旨在提高ICode总线访问的效率。ICode总线上的Prefetch功能可以在CPU请求当前指令线时,同时读取FLASH中的下一条顺序指令线。
如图1所示,通过设置Flash访问控制寄存器(FLASH_ACR)中的PRFTEN位启用预取功能,同时也可以通过使能ICEN位(Instruction cache enable)/DCEN位(Data cache enable)来提升对指令/数据的访问速度。

▲ 图1. FLASH_ACR寄存器及其指令
2.3. 合理利用CCM SRAM
如图2所示,STM32G4的CCM RAM与Cortex™内核紧密结合。这主要为了以最高的系统时钟频率来执行代码,同时避免出现等待状态。因此,与在FLASH中执行代码的情况相比,在CCM RAM中运行代码能够大大减少了关键任务的执行时间。
当代码位于CCM RAM且数据保存在普通SRAM当中时,Cortex-M4内核便处于最优的哈佛配置。
不建议将代码和数据一起放在CCM RAM中,因为这样Cortex内核将不得不从同一个内存中获取代码和数据,造成总线访问冲突,从而影响效率。
具体实现可以参照AN4296,内有详细说明。
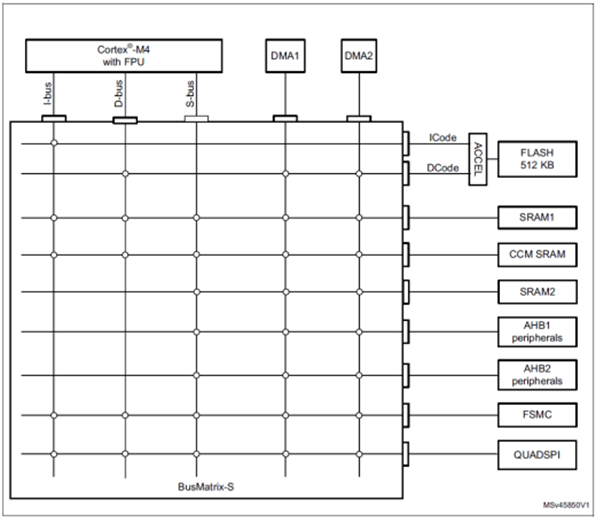
▲ 图2. STM32G4芯片架构
2.4. 代码在SRAM1中运行
如图2所示,CPU可以通过系统总线(S-bus)访问SRAM1。在默认配置下(SYSCFG_MEMRMP),CPU并不可以通过I-bus/D-bus总线访问SRAM1,除非选择了从SRAM1启动(boot from SRAM1)并且配置了物理地址重映射。
因此,当代码与数据都在SRMA1中时,不一定能提升代码的运行效率,因为这样有可能会造成总线竞争,反而影响执行效率,这点需要注意。
2.5. FLASH的单/双BANK模式
在某些具有双Bank FLASH功能的MCU,单双Bank的FALSH读总线宽度不一样,以STM32G474为例,
- 单Bank模式下(DBANK=0),读总线宽度为128 bits;
- 双Bank模式下(DBANK=1),读总线宽度为64 bits;
因此,在不需要双BANK功能下,可以将FLASH配置为单BANK模式,以提升代码在FLASH中运行的效率。可以使用ST的工具软件STM32CubeProgrammer配置芯片的DBANK位。
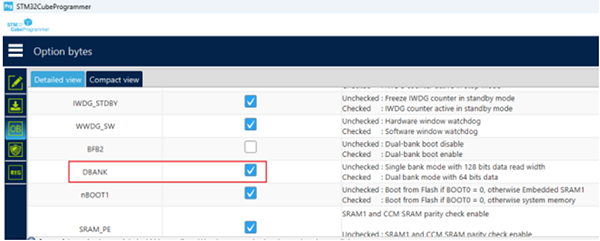
▲ 图3. CubeProgrammer配置STM32G474的选项字节DBANK位
我们使用NUCLEO-G474测试一下,使用一个电机控制环路代码进行测试,以下代码是在FALSH中运行的,当其它条件都不变时,仅仅更改G474的选项字节内的DBANK配置,可以看到运行结果差异还是很大的。测试结果表明,在单BANK模式下,代码运行效率更高。
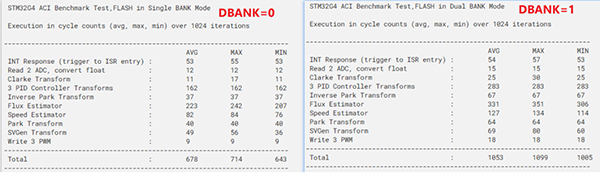
▲ 图4. 电机控制环路代码运行效率测试
- 单Bank模式下(DBANK=0),环路总消耗678 cycles时间;
- 双Bank模式下(DBANK=1),环路总消耗1053 cycles时间;
2.6. 注意使用MicroLib
MicroLib是一个高度优化的库,专为基于ARM的嵌入式应用(用C语言编写)设计。与ARM编译工具链中包含的标准C库相比,MicroLib在代码大小方面具有显著优势,这对于许多嵌入式系统来说非常重要。
但是,需要注意的是,MicroLib某些函数的执行速度可能比ARM编译工具中的标准C库例程稍慢。简言之,MicroLib省空间,并不省时间。
我们使用NUCLEO-G474做一个简单测试,测试一下memset函数在是否使用MicroLib的执行时间。如下图所示,建立一个flolat类型数组,大小2000,用memset进行测试。

图5. 测试memset函数
测试结果表明,当其它条件不变时,仅仅更改编译器的MicroLib设置:
- 当禁用MicroLib时,代码执行时间为24us;
- 当使用MicroLib时,代码执行时间为188us;
可以看到这两种编译方式执行时间相差很大,因此要尤其小心使用编译器的MicroLib配置。
2.7. 优化程序代码分支的写法
Cortex-M4处理器采用三级流水线架构,Prefetch模块旨在提高ICode总线访问的效率。ICode总线的Prefetch功能可以在CPU请求当前指令线的同时,从FLASH中读取下一条顺序指令线。
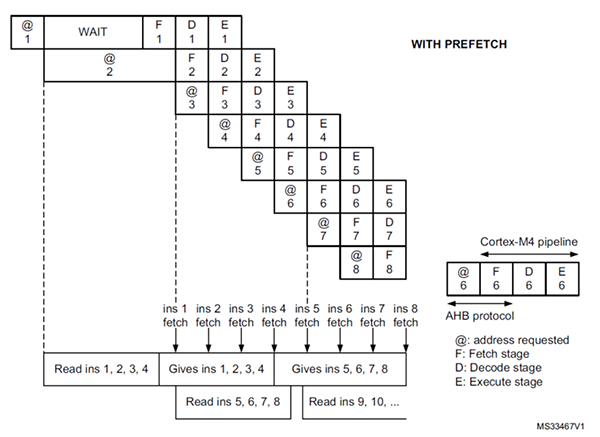
图6. Cortex-M4核三级流水线架构
如果是顺序执行代码,理论上可以达到1cycle/指令的吞吐率。但是遇到分支,麻烦就来了,如果分支预测失败,则需要清空流水线,丢弃所有错误预取的指令,重新从目标地址开始取指,这就需要消耗额外的时间。但如果存在分支套嵌分支的情况,且一半的分支预测失败,则会导致整段代码的运行效率降低10%以上。
因此,在关键的代码(如环路控制计算),需要优化代码的书写逻辑,在不影响代码功能下,尽量减少代码分支(条件判断)。
2.8. 合理使用内联(inline)函数
内联函数可以用来降低程序的运行时间。当内联函数收到编译器的指示时,即可发生内联:把内联函数的函数体在编译器预处理的时候替换到函数调用处,这样代码运行到这里时候,就不需要花时间去调用函数(减少了函数调用过程的入栈和出栈等开销),注意这种替代行为发生在编译阶段而非程序运行阶段。
因此,合理使用内联函数可以提升程序的运行速度,避免了函数调用所带来保存现场、变量弹栈和压栈、跳转新函数、存储函数返回值、执行完返回原现场等开销。
03、小结
对MCU优化计算性能是开发者需要面临的主要问题,对MCU性能的提升是一个系统工程,这需要开发工程师既要熟悉自己的代码及其算法,又需要熟悉MCU的架构以及相应的开发编译环境。本文从以上几个方面提出了对代码优化的方法,以供软件开发人员参考。当然还有其他一些方法:比如优化算法等。
本文对于其它系列MCU,也可以参照此方法酌情进行优化。
来源:STM32
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。









