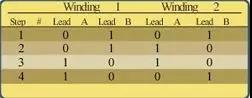
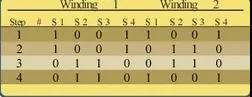
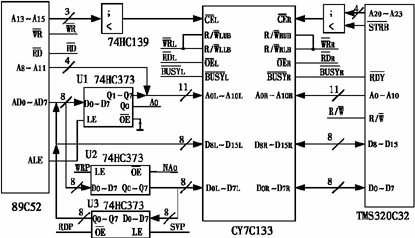
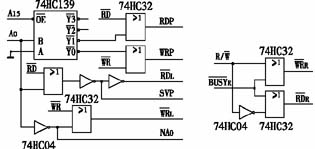
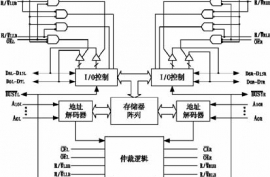
CKS32F4xx系列使用高性能的32位内核,支持浮点运算单元(FPU),同时还支持DSP指令以及存储保护(MPU)用来加强应用的安全性。
DSP介绍
CKS32F4xx系列拥有两个DSP指令:MAC指令(32位乘法累加)和SIMD指令。32位乘法累加(MAC)单元包括新的指令集,能够在单周期内完成一个32×32+64→64的操作或两个16×16的操作。而SIMD指令与硬件乘法器一起工作(MAC),使所有这些指令都能在单个周期内执行。受益于SIMD指令的支持,CKS32F4xx系列能在单周期内完成高达32×32+64→64的运算,为其他任务释放处理器的带宽,而不是被乘法和加法消耗运算资源。
DSP源码库具有以下功能:
BasicMathFunctions
提供浮点数的各种基本运算函数,如向量加减乘除等运算。
CommonTables
arm_common_tables.c文件提供位翻转或相关参数表。
ComplexMathFunctions
复杂数学功能,如向量处理,求模运算的。
ControllerFunctions
控制功能函数。包括正弦余弦,PID电机控制,矢量Clarke变换,矢量Clarke逆变换等。
FastMathFunctions
快速数学功能函数。提供了一种快速的近似正弦,余弦和平方根等,相比CMSIS计算库要快的数学函数。
FilteringFunctions
滤波函数功能,主要为FIR和LMS(最小均方根)等滤波函数。
MatrixFunctions
矩阵处理函数。包括矩阵加法、矩阵初始化、矩阵反、矩阵乘法、矩阵规模、矩阵减法、矩阵转置等函数。
StatisticsFunctions
统计功能函数。如求平均值、最大值、最小值、计算均方根RMS、计算方差/标准差等。
SupportFunctions
支持功能函数,如数据拷贝,Q格式和浮点格式相互转换,Q任意格式相互转换。
TransformFunctions
变换功能。包括复数FFT(CFFT)/复数FFT逆运算(CIFFT)、实数FFT(RFFT)/实数FFT逆运算(RIFFT)、和DCT(离散余弦变换)和配套的初始化函数。
DSP库运行环境搭建
接下来我们讲解如何搭建DSP库运行环境,只要运行环境搭建好了,使用DSP库里面的函数来做相关处理就非常简单了。在MDK里面搭建CKS32F4xx系列的DSP运行环境(使用.lib方式)是很简单的,分为3个步骤:
1、添加文件


2、添加头文件包含路径

3、添加全局宏定义
1,__FPU_USED
2,__FPU_PRESENT
3,ARM_MATH_CM4
4,__CC_ARM
5,ARM_MATH_MATRIX_CHECK
6,ARM_MATH_ROUNDING

CKS32F40_41xxx,USE_STDPERIPH_DRIVER,ARM_MATH_CM4,__CC_ARM,ARM_MATH_MATRIX_CHECK,ARM_MATH_ROUNDING 共6个。
至此,CKS32F4xx系列的DSP库运行环境就搭建完成了。为了方便调试,本章例程我们将MDK的优化设置为-O0优化,以得到最好的调试效果。
DSP FFT测试
关于FFT这里就不再详细介绍。 如果我们要自己实现FFT算法,对于不懂数字信号处理的人来说,是比较难的,不过,DSP库里面就有FFT函数给我们调用,因此我们只需要知道如何使用这些函数,就可以迅速的完成FFT计算。DSP库里面提供了定点和浮点 FFT 实现方式,并且有基4的也有基2的,大家可以根据需要自由选择实现方式。注意:对于基4的FFT输入点数必须是4n,而基2的FFT 输入点数则必须是2n,并且基4的FFT算法要比基2的快。本章我们将采用DSP库里面的基4浮点FFT算法来实现FFT变换,并计算每个点的模值,所用到的函数有:
FFT变换用到的函数
arm_status arm_cfft_radix4_init_f32( arm_cfft_radix4_instance_f32 * S, uint16_t fftLen,uint8_t ifftFlag,uint8_t bitReverseFlag) void arm_cfft_radix4_f32(const arm_cfft_radix4_instance_f32 * S,float32_t * pSrc) void arm_cmplx_mag_f32(float32_t * pSrc,float32_t * pDst,uint32_t numSamples)
arm_cfft_radix4_init_f32用于初始化FFT运算相关参数,其中:fftLen用于指定 FFT长度(16/64/256/1024/4096),本章设置为1024;ifftFlag用于指定是傅里叶变换(0)还是反傅里叶变换(1),本章设置为0;bitReverseFlag用于设置是否按位取反,本章设置为1;最后,所有这些参数存储在一个 arm_cfft_radix4_instance_f32结构体指针S里面。
arm_cfft_radix4_f32就是执行基4浮点FFT运算的,pSrc传入采集到的输入信号数据(实部+虚部形式),同时FFT变换后的数据,也按顺序存放在pSrc里面,pSrc必须大于等于 2倍fftLen长度。另外,S结构体指针参数是先由arm_cfft_radix4_init_f32函数设置好,然后传入该函数的。
arm_cmplx_mag_f32用于计算复数模值,可以对FFT变换后的结果数据,执行取模操作。pSrc为复数输入数组(大小为 2*numSamples)指针,指向FFT变换后的结果;pDst 为输出数组(大小为 numSamples)指针,存储取模后的值;numSamples就是总共有多少个数据需要取模。
通过这三个函数,我们便可以完成 FFT 计算,并取模值。
主函数
int main(void)
{
arm_cfft_radix4_instance_f32 scfft;
float time;
u8 buf[50];
u16 i;
NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2);//设置系统中断优先级分组2
delay_init(168); //初始化延时函数
Debug_USART_Config(); //初始化串口波特率为115200
TIM3_Int_Init(65535,84-1); //1Mhz计数频率,最大计时65ms左右超出
arm_cfft_radix4_init_f32(&scfft,FFT_LENGTH,0,1);//初始化scfft结构体,设定FFT相关参数
while(1)
{
for(i=0;i<fft_length;i++) 生成信号序列
{
fft_inputbuf[2*i]=100+10*arm_sin_f32(2*PI*i/FFT_LENGTH)+30*arm_sin_f32(2*PI*i*4/FFT_LENGTH)+50*arm_cos_f32(2*PI*i*8/FFT_LENGTH); //生成输入信号实部
fft_inputbuf[2*i+1]=0;//虚部全部为0
}
TIM_SetCounter(TIM3,0);//重设TIM3定时器的计数器值
timeout=0;
arm_cfft_radix4_f32(&scfft,fft_inputbuf); //FFT计算(基4)
time=TIM_GetCounter(TIM3)+(u32)timeout*65536;
sprintf((char*)buf,"%0.3fms\r\n",time/1000);
printf("\r\nFFT基4运算运行时间为:\r\n%s", buf);
arm_cmplx_mag_f32(fft_inputbuf,fft_outputbuf,FFT_LENGTH);
printf("\r\n%d point FFT runtime:%0.3fms\r\n",FFT_LENGTH,time/1000);
printf("FFT Result:\r\n");
for(i=0;i<fft_length;i++)< span="">
{
printf("fft_outputbuf[%d]:%f\r\n",i,fft_outputbuf[i]);
}
delay_ms(2000);
delay_ms(2000);
delay_ms(2000);
}
}主函数里面通过我们前面介绍的三个函数:arm_cfft_radix4_init_f32、 arm_cfft_radix4_f32和arm_cmplx_mag_f32来执行FFT变换并取模值。每隔6秒就会重新生成一个输入信号序列,并执行一次FFT计算,将 arm_cfft_radix4_f32 所用时间统计出来,同时将取模后的模值通过串口打印出来。
来源:中科芯MCU
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。