Cortex-M3
1、摘要
Cortex-M内核实现了一个高效异常处理模块,可以捕获非法内存访问和数个程序错误条件。本应用笔记从程序员角度描述Cortex-M Fault异常,并且讲述在软件开发周期中的Fault用法。
2、简介
Cortex-M3(以下简称CM3)和Cortex-M4(以下简称CM4)内核的Fault异常可以捕获非法内存方法和非法编程行为。Fault异常能够检测到以下情况:
总线Fault:在取址、数据读/写、取中断向量、进入/退出中断时寄存器堆栈操作(入栈/出栈)时检测到内存访问错误。
存储器管理Fault:检测到内存访问违反了MPU定义的区域。
用法Fault:检测到未定义的指令异常,未对齐的多重加载/存储内存访问。如果使能相应控制位,还可以检测出除数为零以及其他未对齐的内存访问。
硬Fault:如果上面的总线Fault、存储器管理Fault、用法Fault的处理程序不能被执行(例如禁能了总线Fault、存储器管理Fault、用法Fault异常或者在这些异常处理程序执行过程中又出现了Fault)则触发硬Fault。
本应用笔记描述CM3和CM4的Fault异常用法。系统控制寄存器组中的寄存器可以控制Fault异常或者提供引发异常的原因信息。
更深入的文档
完整的异常描述见《Cortex - M3 Technical Reference Manual》或者《Cortex -M4 Technical Reference Manual》,这两本参考手册都可以在www.arm.com中找到。
另一个很好的参考书是由Joseph Yiu编写的《The Definitive Guide to the ARM Cortex-M3》 (这本书有中文版:宋岩译的《ARM Cortex-M3权威指南》)。
3、Cortex-M Fault异常和寄存器
每个符合CMSIS规范的编译器所提供的启动文件(Startup_device)都会定义好设备所有的异常和中断向量。这些向量表定义了异常或中断处理程序的入口地址。下表给出了一个典型的向量表,Fault异常向量用蓝色标注。
:
:
__Vectors DCD __initial_sp ; 栈顶
DCD Reset_Handler ; 复位处理程序入口
DCD NMI_Handler ; NMI 处理程序入口
DCD HardFaul t_Handler ; 硬Fault处理程序入口
DCD MemManage_Handler ; 存储器管理处理程序入口
DCD BusFault_Handler ; 总线Fault 处理程序入口
DCD UsageFault_Handler ; 用法 Fault 处理程序入口
DCD 0 ; 保留
:
:
通常总是使能硬Fault异常的,硬Fault异常具有固定的优先级,并且优先级高于其它Fault异常以及中断,但低于NMI。硬Fault异常处理程序在以下情况下会被执行:其它非硬Fault异常(非硬Fault异常是指总线、存储器管理和用法Fault 异常,下同。)被禁能,并且这些Fault异常被触发;在执行一个非硬Fault异常处理程序中又产生非硬Fault异常。
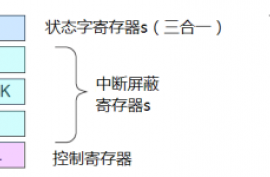
所有非硬Fault具有可编程的优先级。当Cortex-M内核复位后,这些非硬Fault被禁能,你可以在应用软件中通过设置“系统Handler控制及状态寄存器(SHCSR)”来使能非硬Fault异常。这个寄存器属于系统控制模寄存器组(SCB)
3.1 Fault异常的控制寄存器
在这里有必要介绍一下系统控制模块寄存器组(SCB)的成员,这个寄存器组的定义可以在core_cm3.h文件中,该文件属于CMSIS Cortex-M3 内核外设接口抽象层的一部分(关于不清楚CMSIS的,可以自行查找资料)。定义如下:
(1)定义系统控制寄存器组结构体
/** @brief System Control Block (SCB) register structure definition */
typedef struct
{
__I uint32_t CPUID; /*!< Offset: 0x00 CPU ID Base Register*/
__IO uint32_t ICSR; /*!< Offset: 0x04 Interrupt Control State Register*/
__IO uint32_t VTOR; /*!< Offset: 0x08 Vector Table Offset Register*/
__IO uint32_t AIRCR; /*!< Offset: 0x0C Application Interrupt / Reset Control Register*/
__IO uint32_t SCR; /*!< Offset: 0x10 System Control Register*/
__IO uint32_t CCR; /*!< Offset: 0x14 Configuration Control Register*/
__IO uint8_t SHP[12]; /*!< Offset: 0x18 System Handlers Priority Registers (4-7, 8-11, 12-15) */
__IO uint32_t SHCSR; /*!< Offset: 0x24 System Handler Control and State Register */
__IO uint32_t CFSR; /*!< Offset: 0x28 Configurable Fault Status Register*/
__IO uint32_t HFSR; /*!< Offset: 0x2C Hard Fault Status Register*/
__IO uint32_t DFSR; /*!< Offset: 0x30 Debug Fault Status Register */
__IO uint32_t MMFAR; /*!< Offset: 0x34 Mem Manage Address Register*/
__IO uint32_t BFAR; /*!< Offset: 0x38 Bus Fault Address Register*/
__IO uint32_t AFSR; /*!< Offset: 0x3C Auxiliary Fault Status Register*/
__I uint32_t PFR[2]; /*!< Offset: 0x40 Processor Feature Register*/
__I uint32_t DFR; /*!< Offset: 0x48 Debug Feature Register*/
__I uint32_t ADR; /*!< Offset: 0x4C Auxiliary Feature Register*/
__I uint32_t MMFR[4]; /*!< Offset: 0x50 Memory Model Feature Register*/
__I uint32_t ISAR[5]; /*!< Offset: 0x60 ISA Feature Register*/
} SCB_Type;
(2) 定义系统控制寄存器组物理空间基地址
(3) 定义指向系统控制寄存器组的指针
#define SCB ((SCB_Type *)SCB_BASE) /*!< SCB configuration struct * /
通过以上三步,我们就可以使用结构体指针SCB来访问系统控制寄存器组的寄存器了,比如给系统控制寄存器SCR赋值:SCB->SCR=0xFF;
SCB->CCR寄存器控制除数为零和未对齐内存访问是否触发用法Fault。
SCB->SHCSR寄存器可用来使能非硬Fault异常。如果一个非硬Fault异常被禁能并且相关Fault发生,这时异常会升级为硬Fault。SCB->SHP寄存器组控制异常的优先级。
Fault异常控制寄存器列表:
|
地址/访问 |
寄存器 |
复位值 |
描述 |
|
0xE000ED14 RW 特权级 |
SCB->CCR |
0x00000000 |
配置和控制寄存器:包含控制除数为零和未对齐内存访问是否触发用法Fault的使能位。 |
|
0xE000ED18 RW 特权级 |
SCB->SHP[12] |
0x00 |
系统处理程序优先级寄存器:控制异常处理程序的优先级 |
|
0xE000ED24 RW特权级 |
SCB->SHCSR |
0x00000000 |
系统处理程序控制和状态寄存器 |
3.1.1 SCB->CCR 寄存器
蓝色部分控制是否使能相应的用法Fault
|
名称 |
描述 |
|
|
[31:10] |
- |
保留 |
|
[9] |
STKALIGN |
表示进入异常时的堆栈对齐。 0:4字节对齐 1:8字节对齐 进入异常时,处理器使用压入堆栈的PSR位[9]来指示堆栈对齐。从异常返回时,这个堆栈位被用来恢复正确的堆栈对齐。 |
|
[8] |
BFHFNMIGN |
使能时,使得以优先级位-1或-2运行的处理程序忽略加载和存储指令引起的数据总线故障。它用于硬故障、NMI和FAULTMASK升级处理程序中: 0:加载和存储指令引起的数据总线故障会引起锁定。 1:以优先级-1或-2运行的处理程序忽略加载和存储指令引起的数据总线故障。 仅在处理程序和其数据处于绝对安全的存储器时将该位设为1。一般将该位用于探测系统设备和桥接器以检测并纠正控制路径问题。 |
|
[7:5] |
- |
保留 |
|
[4] |
DIV_0_TRP |
当处理器进行除0操作(SDIV或UDIV指令)时,会导致故障或停止。 0:不捕获除以零故障 1:捕获除以零故障。 当该位设为0时,除以零返回的商数为0。 |
|
[3] |
UNALIGN_TRP |
使能非对齐访问捕获: 0:不捕获非对齐半字和字访问 1:捕获非对齐半字和字访问。 如果该位设为1,非对齐访问产生一个使用故障。无论UNALIGN_TRP是否设为1,非对齐的LDM、STM、LDRD和STRD指令总是出错。 |
|
[2] |
- |
保留 |
|
[1] |
USERSETM PEND
|
使能对STIR的无特权软件访问。 0:禁能 1:使能 |
|
[0] |
NONEBASE THRDENA
|
指示处理器如何进入线程模式: 0:处理器仅在没有有效异常时才能够进入线程模式。 1:处理器可以从EXC_RETURN值控制下的任何级别进入线程模式 |
3.1.2 SCB->SHP 寄存器组
以下SCB->SHP 寄存器组的寄存器用来设置异常处理程序的优先级:
SCB->SHP[0]:存储器管理Fault的优先级
SCB->SHP[1]:总线Fault的优先级
SCB->SHP[2]:用法Fault的优先级
为了编程中断和异常的优先级,CMSIS提供了函数NVIC_SetPrioriity和NVIC_GetPriority。这两个函数也位于core_cm3.h中,源码为:
可以通过下面的示例代码更改异常优先级:
:
:
NVIC_SetPriority (MemoryManagement_IRQn, 0xF0);
NVIC_SetPri ority (BusFault_IRQn, 0x80);
NVIC_SetPriority ( UsageFault_IRQn, 0x10);
:
UsageFault_prio = NVIC_GetPriority ( UsageFault_IRQn);
:
:
3.1.3 SCB->SHCSR寄存器
与Fault异常相关位见下表的蓝色部分
|
位 |
名称 |
描述 |
|
[31:19] |
- |
保留 |
|
[18] |
USGFAULTENA |
用法Fault使能位,设为1时使能 |
|
[17] |
BUSFAULTENA |
总线Fault使能位,设为1时使能 |
|
[16] |
MEMFAULTENA |
存储器管理Fault使能位,设为1使能 |
|
[15] |
SVCALLPENDED |
SVC调用挂起位,如果异常挂起,该位读为1 |
|
[14] |
BUSFAULTPENDED |
总线Fault异常挂起位,如果异常挂起,该位读为1 |
|
[13] |
MEMFAULTPENDED |
存储器Fault故障异常挂起位,如果异常挂起,该位读为1 |
|
[12] |
USGFAULTPENDED |
用法Fault异常挂起位,如果异常挂起,该位读为1 |
|
[11] |
SYSTICKACT |
SysTick 异常有效位,如果异常有效,该位读为1 |
|
[10] |
PENDSVACT |
PendSV异常有效位,如果异常有效,该位读为1 |
|
[9] |
- |
保留 |
|
[8] |
MONITORACT |
调试监控有效位,如果调试监控有效,该位读为1 |
|
[7] |
SVCALLACT |
SVC调用有效位,如果SVC调用有效,该位读为1 |
|
[6:4] |
- |
保留 |
|
[3] |
USGFAULTACT |
用法Fault异常有效位,如果异常有效,该位读为1 |
|
[2] |
- |
保留 |
|
[1] |
BUSFAULTACT |
总线Fault异常有效位,如果异常有效,该位读为1 |
|
[0] |
MEMFAULTACT |
存储器管理Fault异常有效位,如果异常有效,该位读为1 |
尽管可以写SCB->SHCSR寄存器的所有位,但建议软件只写异常使能位。下面的例子用于使能所有非硬Fault(存储器管理Fault、总线Fault、用法Fault异常):
SCB - >SHCSR |= 0x00007000; /*enable Usage Fault, Bus Fault, and MMU Fault*/
注:要包含core_cm3.h头文件。
3.2 Fault异常的状态和地址寄存器
Fault状态寄存器组(SCB->CFSR和SCB->HFSR)和Fault地址寄存器组(SCB->MMAR和SCB->BFAR)包含Fault的详细信息以及异常发生时访问的内存地址。
|
地址/访问 |
寄存器 |
复位值 |
描述 |
|
0xE000ED28 RW 特权级 |
SCB->CFSR |
0x00000000 |
可配置Fault状态寄存器:包含指示存储器管理Fault、总线Fault或用法Fault的原因位 |
|
0xE000ED2C RW 特权级 |
SCB->HFSR |
0x00000000 |
硬Fault状态寄存器:包含用于指示硬Fault原因位。 |
|
0xE000ED34 RW特权级 |
SCB->MMFAR |
不可知 |
存储器管理Fault地址寄存器:包括产生存储器管理Fault的位置的地址 |
|
0xE000ED38 RW特权级 |
SCB->BFAR |
不可知 |
总线Fault地址寄存器:包括产生总线Fault的位置的地址 |
3.2.1 SCB->CFSR寄存器
SCB->CFSR寄存器的位分配表:
|
bit31 bit16 |
bit15 bit8 |
bit7 bit0 |
|
存储器管理Fault状态寄存器(MMFSR) |
SCB->CFSR寄存器可以被分成三个组:
存储器管理Fault 状态寄存器:地址0x0xE000ED28,可以按字节访问
总线Fault状态寄存器:地址0xE000ED29,可以按字节访问
用法Fault状态寄存器:地址0xE000ED2A,可以按半字访问
3.2.1.1 存储器管理Fault状态寄存器MMFSR:指示存储器访问Fault的原因
|
名称 |
描述 |
|
|
MMARVALID |
存储器管理Fault地址寄存器(MMAR)有效标志: 1:MMAR中保留一个有效Fault地址。 如果发生了一个存储器管理Fault,并由于优先级的原因升级成一个硬Fault,那么硬Fault处理程序必须将该位设为0。 |
|
|
[6:5] |
- |
保留 |
|
[4] |
MSTKERR |
进入异常时的入栈操作引起的存储器管理Fault: 0:无入栈Fault 1:进入异常时的入栈操作引起了一个或一个以上的访问违犯。 当该位设为1时,依然要对SP进行调节,并且堆栈的上下文区域的值可能不正确。处理器没有向MMAR中写入Fault地址。 |
|
[3] |
MUNSTKERR |
异常返回时的出栈操作引起的存储器管理Fault: 0:无出栈Fault 1:异常返回时的出栈操作已引起一个或一个以上的访问违犯. 该Fault与处理程序相连,这意味着当该位为1时,原始的返回堆栈仍然存在。 处理器不能对返回失败的SP进行调节,并且不会执行新的存储操作。处理器没有向MMAR中写入Fault地址。 |
|
[2] |
- |
保留 |
|
[1] |
DACCVIOL |
数据访问违犯标志: 0:无数据访问违犯Fault 1:处理器试图在不允许执行操作的位置上进行加载和存储。 当该位为1时,异常返回的压入堆栈的PC值指向出错指令。处理器已在MMAR中加载了目标访问的地址。 |
|
[0] |
IACCVIOL |
指令访问违犯标志: 0:无指令访问违犯错误 1:处理器试图从不允许执行操作的位置上进行指令获取。 即使MPU被禁能,这一故障也会在XN(CM3内核的0xE0000000~0xFFFFFFFF区域)区寻址时发生。 当该位为1时,异常返回的压入堆栈的PC值指向出错指令。处理器没有向MMAR中写入故障地址。 |
3.2.1.2 总线Fault状态寄存器BFSR:指示总线访问Fault原因
|
位 |
名称 |
描述 |
|
[7] |
BFARVALID |
总线Fault地址寄存器(BFAR)有效标志: 0:BFAR中的值不是有效故障地址 1:BFAR中保留一个有效故障地址。 在地址已知的总线故障发生后处理器将该位设为1。该位可以被其他Fault清零,例如之后发生的存储器管理Fault。 如果发生总线Fault,并由于优先级原因升级为一个硬Fault,那么硬Fault处理程序必须将该位设为0。 |
|
[6:5] |
- |
保留 |
|
[4] |
STKERR |
进入异常时的入栈操作引起的总线Fault: 0:无入栈故障 1:进入异常时的入栈操作已引起一个或一个以上的总线故障。 当处理器将该位设为1时,依然要对SP进行调节,并且堆栈的上下文区域的值可能不正确。处理器没有向BFAR中写入Fault地址。 |
|
[3] |
UNSTKERR |
0:无出栈Fault 1:异常返回时的出栈操作已引起一个或一个以上的总线Fault。 该Fault与处理程序相连, 这意味着当处理器将该位设为1时,原始的返回堆栈仍然存在。处理器不能对返回失败的SP进行调节,并且不会执行新的存储操作,也未向BFAR中写入Fault地址。 |
|
[2] |
IMPRECISERR |
非精确数据总线错误: 0:无非精确数据总线错误 1:已发生一个数据总线错误,但是堆栈帧中的返回地址与引起错误的指令无关。 当处理器将该位设为1时,不向BFAR中写入Fault地址。 这是一个异步Fault。因此,如果在当前进程的优先级高于总线Fault优先级时检测到该Fault,总线Fault被挂起并仅在处理器从所有更高优先级进程中返回时开始变为有效。如果在处理器进入非精确总线Fault的处理程序前发生一个精确Fault,那么处理程序同时对IMPRECISERR 和其中一个精确Fault状态位进行检测,判断它们是否置位为1。 |
|
[1] |
PRECISERR |
精确数据总线错误: 0:非精确数据总线错误 1:已发生一个数据总线错误,且异常返回的压入堆栈的PC值指向引起Fault的指令。 当处理器将该位设为1时,向BFAR中写入Fault地址。 |
|
[0] |
IBUSERR |
指令总线错误: 0:无指令总线错误 1:指令总线错误。 处理器检测到预取指令时的指令总线错误,但仅在其试图签发Fault指令时才将IBUSERR 标志设为1。 当处理器将该位设为1时,不向BFAR中写入Fault地址。 |
3.2.1.3 用法Fault状态寄存器UFSR:指示产生用法Fault的原因
|
位 |
名称 |
描述 |
|
[15:10] |
- |
保留 |
|
[9] |
DIVBYZERO |
0:无除以零Fault或除以零捕获未使能 1:处理器已执行SDIV或UDIV指令(除以零)。 当处理器将该位设为1时,异常返回的压入堆栈的PC值指向执行除以零的指令。 注:通过将CCR中的DIV_0_TRP位设为1使能除以零捕获,默认是不使能的。 |
|
[8] |
UNALIGNED |
0:无非对齐访问Fault,或非对齐访问捕获未使能 1:处理器已进行了一次非对齐的存储器访问。 注:通过将CCR中的UNALIGN_TRP位设为1来使能非对齐访问捕获,默认是不使能的。非对齐的LDM、STM、LDRD和STRD指令总是出错,与UNALIGN_TRP的设置无关。 |
|
[7:4] |
- |
保留 |
|
[3] |
NOCP |
无协处理器用法Fault。处理器不支持协处理器指令: 0:试图访问一个协处理器未引起用法Fault 1:处理器已试图访问一个协处理器。 |
|
[2] |
INVPC |
EXC_RETURN的无效PC加载引起的无效PC加载用法Fault: 0:没有发生无效PC加载用法Fault 1:处理器已试图将EXC_RETURN非法载入PC,作为一个无效的上下文或一个无效的EXC_RETURN值。 当该位被设为1时,异常返回的压入堆栈的PC值指向尝试执行非法PC加载的指令。 |
|
[1] |
INVSTATE |
无效状态用法Fault: 0:未发生无效状态用法Fault 1:处理器已试图执行一个非法使用EPSR的指令。 当该位设为1时,异常返回的压入堆栈的PC值指向一个尝试非法使用EPSR的指令。 如果一个未定义的指令使用了EPSR,则该位不被置位为1。 |
|
[0] |
UNDEFINSTR |
未定义的指令用法Fault: 0:无未定义的指令用法Fault 1:处理器已试图执行一个未定义的指令。当该位设为1时,异常返回的压入堆栈的PC值指向未定义的指令。 未定义的指令是一条不能被处理器译码的指令。 |
3.2.2 SCB->HSFR寄存器
SCB->HSFR寄存器提供关于激活硬Fault处理程序的事件的信息,写入1清零相应位。
|
位 |
名称 |
描述 |
|
[31] |
DEBUGEVT |
硬Fault因调试事件产生,保留供调试使用。对寄存器执行写操作时,必须向该位写入0;否则,该行为不可预知。 |
|
[30] |
FORCED |
指示硬Fault是否由上访产生,非硬Fault的处理程序无法执行时,会上访成硬Fault。 0:硬Fault不是因为非硬Fault上访产生的 1:硬Fault是通过非硬Fault上访产生的。 当该位设为1时,硬Fault处理程序必须读其他Fault状态寄存器以找出Fault原因。 |
|
[29:2] |
- |
保留 |
|
[1] |
VECTTBL |
指示一个在异常处理过程中读向量表而引起的总线Fault: 0:读向量表未引起总线Fault 1:读向量表引起了总线Fault。 这一错误通常情况下都由硬Fault处理程序来处理。 |
|
[0] |
- |
保留 |
3.2.3 SCB->MMFAR和SCB->BFAR寄存器
为了确定产生了哪个Fault异常以及什么原因引起的Fault异常,你需要检测Fault状态寄存器。
如果SCB->CFSR寄存器的BFARVALID位有效(为1),则SCB->BFAR寄存器的值表示引起总线Fault的内存地址。
如果SCB->CFSR寄存器的MMFARVALID位有效(为1),则SCB->MMFAR寄存器的值表示引起存储器管理Fault的内存地址。
一、什么是栈对齐?
栈的字节对齐,实际是指栈顶指针须是某字节的整数倍。因此下边对系统栈与MSP,任务栈与PSP,栈对齐与SP对齐 这三对概念不做区分。另外下文提到编译器的时候,实际上是对编译器汇编器连接器的统称。
之前对栈的8字节对齐理解的不透,就在网上查了好多有关栈字节对齐、还有一些ARM对齐伪指令的资料信息,又做了一些实验,把这些零碎的信息拼接在一起,总觉得理解透这个问题的话得长篇大论了。结果昨天看了AAPCS手册、然后查到了没有使用PRESERVE8伪指令出现错误的实例,突然觉得长篇大论不存在了,半篇小论这问题就能理顺了。
二、AAPCS栈使用规约
在ARM上编程,但凡涉及到调用,就需要遵循一套规约AAPCS:《Procedure Call Standard for the ARM Architecture》。这套规约里面对栈使用的约定如下:
5.2.1.1
Universal stack constraints
At all times the following basic constraints must hold:
Stack-limit < SP <= stack-base. The stack pointer must lie within the extent of the stack.
SP mod 4 = 0. The stack must at all times be aligned to a word boundary.
A process may only access (for reading or writing) the closed interval of the entire stack delimited by [SP, stack-base – 1] (where SP is the value of register r13).
Note
This implies that instructions of the following form can fail to satisfy the stack discipline constraints, even when reg points within the extent of the stack.
ldmxx reg, {..., sp, ...} // reg != sp
If execution of the instruction is interrupted after sp has been loaded, the stack extent will not be restored, so restarting the instruction might violate the third constraint.
5.2.1.2
Stack constraints at a public interface
The stack must also conform to the following constraint at a public interface:
SP mod 8 = 0. The stack must be double-word aligned.
可以看到,规约规定,栈任何时候都得4字节对齐,在调用入口得8字节对齐。
在这个约定里,栈的4字节对齐确实得任何时候都遵守,而且你想不遵守都难,因为SP的最后两位是硬件上保持0的。而对于8字节对齐,这就需要码农和编译器配合着来。需要说明的一点是,8字节对齐即使不遵守,一些情况下也没问题,只要主调和被调用例程两边把堆栈使用,传参,返回等处理好就行,也就是说两边有自己的一套约定就行。但是有时候,主调这边在调用严格遵守AAPCS的函数时,没有将栈保持在8字节对齐上,那就会出问题。
三、如何编程?
在Cortex-M3上编程时,对于AAPCS栈使用约定的遵守,总的来说就两条:
1. 汇编文件中需要我们亲自动手来保证遵守AAPCS栈使用约定。
(特别注意每次从汇编进入C的世界时,要保证汇编部分的编码在调用c接口时栈是8字节对齐的,不要疏忽了,因为c编译器可不负责调整。c编译器说你得送给我的SP就是8字节对齐的,我才能保证接下来的C部分没有结束之前,遵守AAPCS栈使用约定)
2. 在C文件中,由编译器来处理。
四、补充:
1. 由于程序的入口点为复位中断响应函数,一般我们都写在启动代码里,通常是一个汇编文件,然后经由汇编进入到C程序的main入口处,在调用main的时刻,为遵循AAPCS,就得在此时保持8字节对齐。
2. 对于MSP,Keil MDK为我们提供了一个用来初始化C运行库环境的函数_main,这个函数会调用_user_setup_stackheap函数,该函数将MSP的低三位清零,然后在进入main之前不对其进行更改,这样在进入main的时刻,MSP保证为8字节对齐的。
3. 对于PSP,一般在上多任务OS时会用它,对于PSP我们要比MSP更为操心点,因为MSP起码还可以通过调用_main来跳进main的方式保证进入C世界的时候是遵守约定的。而PSP全靠自己来保证每次进入C世界时是8字节对齐。
4. 另外只要是汇编文件,可配合使用汇编命令armasm --diag_warning 1546,这样汇编器就会对一些SP没有8字节对齐的地方给出警告,但是我发现汇编器并不能保证检测到所有对SP造成8字节不对齐的操作,例如直接给SP载入一个立即数这种,汇编器就发现不了。我并没有对所有会影响SP的指令进行测试(原因是不熟悉。。。),不知道1546这个警告能覆盖多少指令,所以总的来讲,对汇编文件就是睁大自己的钛合金眼,争取大部分工作都放到C中去。
五. Cortex-M3 中断控制器的栈对齐调整功能(该功能在r2p0版本以后的内核中均默认开启,STKALIGN位默认为1)
Cortex M3 NVIC CCR寄存器(控制与配置寄存器)的STKALIGN位置1,那么在发生中断时,进入中断响应函数前,内核会首先检查当前正在使用的栈指针是否8字节对齐,如果是,则正常将xPSR,PC,LR,SP,R0-R3入栈,如果不是,则先把SP-4,调整为8字节对齐,然后将xPSR第九位置1,接着把xPSR,PC,LR,SP,R0-R3入栈,再然后才进入中断响应函数。这样可以保证程序在运行过程中,如果在栈没有发生4字节对齐的地方发生中断了,进入到中断响应函数的时候也是遵守AAPCS栈使用约定的。如果中断服务程序是做任务切换的,那么前面的情况就是将任务栈调整为对齐,然后进入异常服务程序后使用系统栈,那如果系统栈本来就是不对齐的呢?通过中断来做任务切换的情况下,中断控制器并不会对系统栈进行调整,怎么办?其实这也不用担心,以μC/OS-II为例,在cortex-m3上通常使用PendSV异常来做任务切换,即将OSCtxSw以及OSIntCtxSw都设为仅完成PendSV异常触发功能,然后在PendSV异常服务程序中进行任务切换。由于上电时刻系统处于特权级模式,只要我们保证从上电开始到第一次系统调用,使用的栈都是系统栈MSP就可以了,这样即使第一次要进入任务切换时MSP不对齐,中断向量控制器也会给调整为8字节对齐状态,虽然这个第一次任务切换后除了中断再也不会使用MSP,但只要我们同时保证所有汇编部分都不会破坏8字节对齐规约,那么从此以后MSP都会是8字节对齐的。
六、关于ALIGN属性 与 PRESERVE8伪指令
在CORTEX M3芯片的启动代码中,这两个伪指令并非必不可少,可以不要这两个伪指令。但是有了这两个伪指令,可以在确保遵守AAPCS的道路上加一道保险,使得AAPCS栈使用约定的遵守在实际编程时变得稍微容易点。
当在段定义头(即AREA伪指令的相关代码)当中使用ALIGN=?时,ALIGN属性的作用为设定该代码段或数据段的首址的对齐位置,例如ALIGN=3就表示,该段首址将被安排在2^3=8字节对齐处。需要注意的是,除了AREA的ALIGN属性,还有一个同名的ALIGN指令,ALIGN指令使用在段内部的,用来调整ALIGN指令下一条命令或数据的对齐位置。
而PRESERVE8伪指令并不会对栈进行任何修改。PRESERVE8伪指令的使用有四种方法,分别如下,其中1、2的用法是等价的:
1. PRESERVE8
2. PRESERVE8 {TRUE}
3. PRESERVE8 {FALSE}
如果不写,那么由编译器来决定在编译过程中将汇编文件标识为PRES8属性还是~PRES8属性(也即加还是不加该伪指令),但经过实验,发现编译器在加不加这条伪指令上表现的并不完全可靠。。。所以最好明确的加上是 PRESERVE8 {TRUE}还是PRESERVE8 {FALSE}。那么这条伪指令起什么作用呢?
如果你想要告诉汇编器说:“在我这个汇编文件中保证栈的8字节对齐,我这个文件对栈的任何时刻的任何操作都是8字节对齐的”,那么你就把PRESERVE8伪指令用在汇编文件中,用以向汇编器通知前面你的保证内容。汇编器就知道你这个汇编文件是8字节对齐靠谱选手,将该文件标识为PRES8属性,然后如果在你这个汇编中调用了标示了需要8字节对齐属性的文件中的函数,连接的时候就不会报错。但是假如你把这个汇编文件标示为PRESERVE8 {FALSE},然后你又在这个文件中调用了标示了需要8字节对齐属性的文件中的函数,连接时就会给出错误信息。
那么什么是标示了需要8字节对齐属性的文件呢?如果你的某个汇编文件,某些操作一定要栈8字节对齐才行,那么你就需要使用REQUIRE8伪指令来通知汇编器将该文件标识为REQ8属性,然后这个文件就是所谓的“标示了需要8字节对齐属性的文件”。
在文件较多,文件之间调用由繁多的情况下,通过PRESERVE8和REQUIRE8的配合,就能够在连接期间由编译器检查出我们写代码时不小心造成的破坏8字节对齐模块对需要8字节对齐模块的调用(经过实验发现,汇编之间是给出警告,汇编调用C则是给出错误,由于C文件中并不能直接用REQUIRE8,所以我猜编译器将C文件都通通标识为REQ8属性了,所以才会出错)。
REQUIRE8的用法同PRESERVE8。
文章来源: 博客园
CM3 只有一个单一固定的存储器映射。这一点极大地方便了软件在各种 CM3 单片机间的移植。
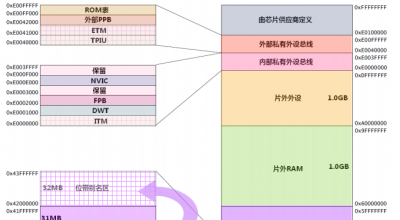
存储空间的一些位置用于调试组件等私有外设,这个地址段被称为“私有外设区”。私有外设区的组件包括:闪存地址重载及断点单元(FPB),数据观察点单元(DWT),仪器化跟踪宏单元(ITM),嵌入式跟踪宏单元(ETM),跟踪端口接口单元(TPIU), ROM 表。
CM3的地址空间是 4GB, 程序可以在代码区,内部 SRAM 区以及外部 RAM 区中执行。但是因为指令总线与数据总线是分开的,最理想的是把程序放到代码区,从而使取指和数据访问各自使用自己的总线,并行不悖。

1、代码区
存放指令和数据,取指通过指令码(ICode)总线,数据访问借助数据码(DCode)总线。
2、片上SRAM
内部SRAM 区的大小是 512MB,用于让芯片制造商连接片上的 SRAM,这个区通过系统总线来访问。在这个区的下部,有一个 1MB 的区间,被称为“位带区”。该位带区还有一个对应的、 32MB 的“位带别名(alias)区”,容纳了 8M 个“位变量”(对比 8051 的只有 128 个位变量)。位带区对应的是最低的 1MB 地址范围,而位带别名区里面的每个字对应位带区的一个比特。位带操作只适用于数据访问,不适用于取指。通过位带的功能,可以把多个布尔型数据打包在单一的字中,却依然可以从位带别名区中,像访问普通内存一样地使用它们。位带别名区中的访问操作是原子的。
3、片上外设
512M由片上外设(的寄存器)使用。这个区中也有一条 32MB 的位带别名,以便于快捷地访问外设寄存器,用法与内部 SRAM 区中的位带相同。
4、2个1G空间
分别用于连接外部 RAM 和外部设备,它们之中没有位带。两者的区别在于外部 RAM 区允许执行指令,而外部设备区则不允许。
5、最后0.5G
包括了系统级组件,内部私有外设总线 s,外部私有外设总线 s,以及由提供者定义的系统外设。
私有外设总线有两条:
AHB 私有外设总线,只用于CM3内部的AHB外设,它们是:NVIC, FPB, DWT和ITM。
APB 私有外设总线,既用于CM3内部的APB设备,也用于外部设备(这里的“外部”是对内核而言)。CM3允许器件制造商再添加一些片上APB外设到APB私有总线上,它们通过APB接口来访问。
文章来源:CSDN博客

1、通用目的寄存器R0~R7
R0-R7 也被称为低组寄存器。所有指令都能访问它们。它们的字长全是 32 位,复位后的初始值是不可预料的。
2、通用目的寄存器 R8-R12
R8-R12 也被称为高组寄存器。这是因为只有很少的 16 位 Thumb 指令能访问它们, 32 位的thumb-2 指令则不受限制。它们也是 32 位字长,且复位后的初始值是不可预料的。
3、特殊功能寄存器

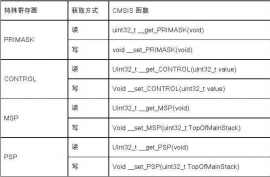
程序状态寄存器:APSR, IPSR, EPSR ---- MRS/MSR

APSR:
N:负条件码标志位,运算结果小于0,N=1, 大于等于0,N=0;
Z:零条件码标志位,运算结果为0,Z=1;
C:进位条件码标志位,运算指令产生进位(无符号加法溢出),C=1;
V:溢出条件码标志位,运算溢出(有符号加法溢出), V=1;
Q:饱和条件码标志位;
IPSR:处于线程模式时,该位域为0;在手柄模式下,该位域为当前异常的异常号。
EPSR:
T:Thumb状态, T=1,ARM状态,T=0;
PRIMASK, FAULTMASK 和 BASEPRI:控制异常的使能和除能

控制寄存器CONTROL:其一用于定义特权级别,其二用于选择当前使用哪个堆栈指针。

4、堆栈指针R13
R13 是堆栈指针。在 CM3 处理器内核中共有两个堆栈指针,于是也就支持两个堆栈。当引用 R13(或写作 SP)时,引用到的是当前正在使用的那一个,另一个必须用特殊的指令来访问( MRS,MSR指令)。
主堆栈指针(MSP),或写作 SP_main。这是缺省的堆栈指针,它由 OS 内核、异常服务例程以及所有需要特权访问的应用程序代码来使用。
进程堆栈指针(PSP),或写作 SP_process。用于常规的应用程序代码(不处于异常服用例程中时)。
5、连接寄存器R14
R14 是连接寄存器( LR)。在一个汇编程序中,你可以把它写作 both LR 和 R14。 LR 用于在调用子程序时存储返回地址。例如,当你在使用 BL(分支并连接, Branch and Link)指令时,就自动填充 LR的值。
6、程序计数器R15
R15 是程序计数器,在汇编代码中一般我们都都叫它的外号“ PC”。因为 CM3 内部使用了指令流水线,读 PC 时返回的值是当前指令的地址+4。
文章来源:CSDN博客


最近在关注Cortex-M处理器,针对目前进入大众视野的M0、M3、M4做了如下简单对比,内容来自ARM等官网,这里仅仅是整理了下,看起来更直观点,
Cortex-M 系列针对成本和功耗敏感的 MCU 和终端应用(如智能测量、人机接口设备、汽车和工业控制系统、大型家用电器、消费性产品和医疗器械)的混合信号设备进行过优化。.
一、比较 Cortex-M 处理器

Cortex-M 系列处理器都是二进制向上兼容的,这使得软件重用以及从一个

Cortex-M 处理器无缝发展到另一个成为可能。
M Cortex-M 技术

CMSIS
ARM Cortex 微控制器软件接口标准 (CMSIS) 是 Cortex-M 处理器系列的与供应商无关的硬件抽象层。 使用 CMSIS,可以为接口外设、实时操作系统和中间件实现一致且简单的软件接口,从而简化软件的重用、缩短新微控制器开发人员的学习过程,并缩短新产品的上市时间。
深入:嵌套矢量中断控制器 (NVIC)
NVIC 是 Cortex-M 处理器不可或缺的部分,它为处理器提供了卓越的中断处理能力。 Cortex-M 处理器使用一个矢量表,其中包含要为特定中断处理程序执行的函数的地址。接受中断时,处理器会从该矢量表中提取地址。
为了减少门数并增强系统灵活性,Cortex-M 处理器使用一个基于堆栈的异常模型。出现异常时,系统会将关键通用寄存器推送到堆栈上。完成入栈和指令提取后,将执行中断服务例程或故障处理程序,然后自动还原寄存器以使中断的程序恢复正常执行。使用此方法,便无需编写汇编器包装器了(而这是对基于 C 语言的传统中断服务例程执行堆栈操作所必需的),从而使得应用程序的开发变得非常容易。NVIC 支持中断嵌套(入栈),从而允许通过运用较高的优先级来较早地为某个中断提供服务。
在硬件中完成对中断的响应
Cortex-M 系列处理器的中断响应是从发出中断信号到执行中断服务例程的周期数。它包括:
● 检测中断
● 背对背或迟到中断的最佳处理(参见下文)
● 提取矢量地址
● 将易损坏的寄存器入栈跳转到中断处理程序


这些任务在硬件中执行,并且包含在为 Cortex-M 处理器报出的中断响应周期时间中。在其他许多体系结构中,这些任务必须在软件的中断处理程序中执行,从而引起延迟并使得过程十分复杂。
NVIC 中的尾链
在背对背中断的情况下,传统系统会重复完整的状态保存和还原周期两次,从而导致更高的延迟。Cortex-M 处理器通过在 NVIC 硬件中实现尾链技术简化了活动中断和挂起的中断之间的转换。处理器状态会在比软件实现时间更少的周期内自动保存在中断条目上并在中断退出时还原,从而显著提升低 MHz 系统的性能。
NVIC 对迟到的较高优先级中断的响应
如果在为上一个中断执行堆栈推送期间较高优先级的中断迟到,NVIC 会立即提取新的矢量地址来为挂起的中断提供服务,如上所示。Cortex-M NVIC 对这些可能性提供具有确定性的响应并支持迟到和抢占。
NVIC 进行的堆栈弹出抢占

同样,如果异常到达,NVIC 将放弃堆栈弹出并立即为新的中断提供服务,如上所示。通过抢占并切换到第二个中断而不完成状态还原和保存,NVIC 以具有确定性的方式实现了缩短延迟。
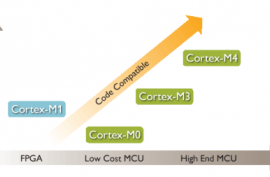
二、为什么选择 1、为什么选择Cortex-M0
能耗最低的最小 ARM 处理器
Cortex-M0 的代码密度和能效优势意味着它是各种应用中 8/16 位设备的自然高性价比换代产品,同时保留与功能丰富的 Cortex-M3 处理器的工具和二进制向上兼容性。 超低的能耗
Cortex-M0 处理器在不到 12 K 门的面积内能耗仅有 85 µW/MHz(0.085 毫瓦),所凭借的是作为低能耗技术的领导者和创建超低能耗设备的主要推动者的无与伦比的 ARM 专门技术。
简单
指令只有 56 个,这样您便可以快速掌握整个 Cortex-M0 指令集(如果需要);但其 C 语言友好体系结构意味着这并不是必需的。可供选择的具有完全确定性的指令和中断计时使得计算响应时间十分容易。
优化的连接性
设计为支持低能耗连接,如 Bluetooth Low Energy (BLE)、IEEE 802.15 和 Z-wave,特别是在这样的模拟设备中:这些模拟设备正在增加其数字功能,以有效地预处理和传输数据。
2、为什么选择Cortex-M3
提供更高的性能和更丰富的功能
于 2004 年引进、最近通过新技术进行了更新并更新了可配置性的 Cortex-M3,是专门针对微控制器应用开发的主流 ARM 处理器。
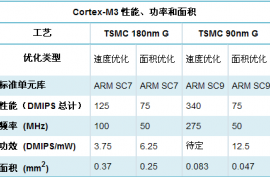
性能和能效
具有高性能和低动态能耗,Cortex-M3 处理器提供领先的功效:在 90nmG 基础上为 12.5 DMIPS/mW。将集成的睡眠模式与可选的状态保留功能相结合,Cortex-M3 处理器确保对于同时需要低能耗和出色性能的应用不存在折衷。
全功能
该处理器执行 Thumb-2 指令集以获得最佳性能和代码大小,包括硬件除法、单周期乘法和位字段操作。Cortex-M3 NVIC 在设计时是高度可配置的,最多可提供 240 个具有单独优先级、动态重设优先级功能和集成系统时钟的系统中断。
丰富的连接

功能和性能的组合使基于 Cortex-M3 的设备可以有效处理多个 I/O 通道和协议标准,如 USB OTG (On-The-Go)。
3、为什么选择Cortex-M4 ®
目标用用:专门面向电动机控制、汽车、电源管理、嵌入式音频和工业自动化市场的新兴类别的灵活解决方案。
曾获大奖的高能效数字信号控制
Cortex-M4 提供了无可比拟的功能,以将 32 位控制与领先的数字信号处理技术集成来满足需要很高能效级别的市场。
易于使用的技术
Cortex-M4 通过一系列出色的软件工具和 Cortex 微控制器软件接口标准 (CMSIS) 使信号处理算法开发变得十分容易。
三、规范
1、M0
ARM Cortex-M0 处理器执行 Thumb 指令集,包括少量使用 Thumb-2 技术的 32 位指令。这是 ARM Cortex-M3 和 ARM Cortex-M4 支持的指令集的二进制向上可兼容子集。
2、

M3

内核面积、频率范围和功耗取决于工艺、库和优化。上面引用的数字是使用通用 TSMC 工艺技术和 ARM 物理 IP 标准单元库和 RAM 的合成核心的说明。面积数字包括
CM3Core、嵌套向量中断控制器 (NVIC) 和总线矩阵,但不包括可选组件(包括内存保护单元、嵌入式跟踪宏单元、断点单元、数据检测点单元和跟踪端口接口单元)。
速度优化的实现是指为了实现目标频率性能而做出的库选择、合成流决策和折衷。面积优化的实现是指为了实现目标面积密度而做出的库选择、合成流决策和折衷。
3、M4



内核面积、频率范围和功耗取决于工艺、库和优化。上面引用的数字是使用低功耗工艺技术和 ARM 物理 IP 标准单元库和 RAM 的合成内核的说明。面积数字包括中央内核(包括 DSP 扩展、嵌套矢量中断控制器 (NVIC) 和总线矩阵),但不包括可选组件

(包括内存保护单元、嵌入式跟踪宏单元、断点单元、数据检测点单元和 Trace Port Interface Unit。
速度优化的实现是指为了实现目标频率性能而做出的库选择、合成流决策和折衷。面积优化的实现是指为了实现目标面积密度而做出的库选择、合成流决策和折衷。
以下的一点为M4页面特有的介绍:
系统 IP
系统 IP 组件对于在芯片上构建复杂的系统至关重要,通过利用系统 IP 组件,开发人员可以显著缩短开发和验证周期,从而节省成本并缩短产品的上市时间。

来源:百度文库






















一、NVIC概览 ——嵌套中断向量表控制器
NVIC 的寄存器以存储器映射的方式来访问,除了包含控制寄存器和中断处理的控制逻辑之外, NVIC 还包含了 MPU、 SysTick 定时器以及调试控制相关的寄存器。
NVIC 共支持 1 至 240 个外部中断输入(通常外部中断写作 IRQs)。具体的数值由芯片厂商在设计芯片时决定。此外, NVIC 还支持一个“永垂不朽”的不可屏蔽中断( NMI)输入。
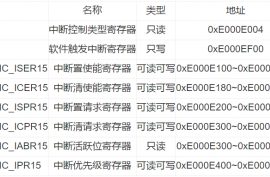
NVIC 的访问地址是 0xE000_E000。所有 NVIC 的中断控制/状态寄存器都只能在特权级下访问。不过有一个例外——软件触发中断寄存器可以在用户级下访问以产生软件中断。所有的中断控制/状态寄存器均可按字/半字/字节的方式访问。
二、中断配置

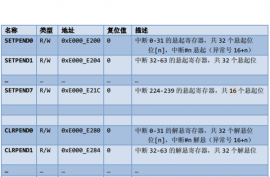
1、中断的使能与除能(SETENA/CLRENA)

2、中断置请求与清请求(SETPEND/CLRPEND)
如果中断发生时,正在处理同级或高优先级异常,或者被掩蔽,则中断不能立即得到响应。此时中断被悬起。

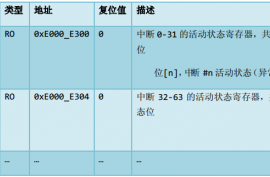
3、中断活跃位寄存器
ACTIVE寄存器族 0xE000_E300_0xE000_E31C

三、软件中断
软件中断,包括手工产生的普通中断,能以多种方式产生。最简单的就是使用相应的SETPEND寄存器;而更专业更快捷的作法,则是通过使用软件触发中断寄存器STIR
软件触发中断寄存器STIR(地址:0xE000_EF00)

注意:系统异常( NMI,faults, PendSV等),不能用此法悬起。而且缺省时根本不允许用户程序改动NVIC寄存器的值。如果确实需要,必须先在NVIC的配置和控制寄存器(0xE000_ED14)中,把比特1(USERSETMPEND)置位,才能允许用户级下访问NVIC的STIR。
四、SysTick定时器
SysTick定时器被捆绑在NVIC中,用于产生SysTick异常(异常号: 15)。
Cortex-M3处理器内部包含了一个简单的定时器。因为所有的CM3芯片都带有这个定时器,软件在不同 CM3器件间的移植工作就得以化简。该定时器的时钟源可以是内部时钟( FCLK, CM3上的自由运行时钟),或者是外部时钟(CM3处理器上的STCLK信号)。不过, STCLK的具体来源则由芯片设计者决定,因此不同产品之间的时钟频率可能会大不相同。因此,需要检视芯片的器件手册来决定选择什么作为时钟源。
SysTick定时器能产生中断, CM3为它专门开出一个异常类型,并且在向量表中有它的一席之地。它使操作系统和其它系统软件在CM3器件间的移植变得简单多了,因为在所有CM3产品间,SysTick 的处理方式都是相同的。
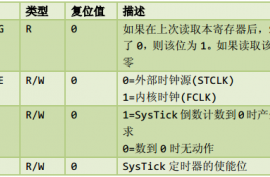
SysTick控制及状态寄存器(地址:0xE000_E010)

SysTick重装载数值寄存器(地址:0xE000_E014)

SysTick当前数值寄存器(地址:0xE000_E018)

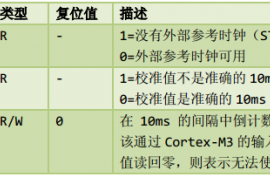
SysTick校准数值寄存器(地址:0xE000_E01C)

校准值寄存器提供了这样一个解决方案:它使系统即使在不同的CM3产品上运行,也能产生恒定的SysTick中断频率。最简单的作法就是:直接把TENMS的值写入重装载寄存器,这样一来,只要没突破系统的“弹性极限”,就能做到每10ms来一次 SysTick异常。如果需要其它的SysTick异常周期,则可以根据TENMS的值加以比例计算。只不过,在少数情况下, CM3芯片可能无法准确地提供TENMS的值(如, CM3的校准输入信号被拉低),所以为保险起见,最好在使用TENMS前检查器件的参考手册。
作者:a1314521531
来源:CSDN(版权归著作者所有)




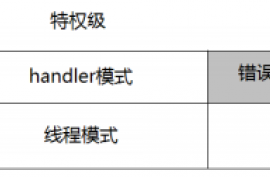
一、工作模式
线程模式和手柄模式。

当处理器处在线程状态下时,既可以使用特权级,也可以使用用户级;另一方面, handler模式总是特权级的。在复位后,处理器进入线程模式+特权级。
二、异常和中断
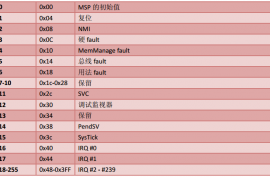
Cortex-M3 支持大量异常,包括 16-4-1=11个系统异常,和最多 240 个外部中断——简称 IRQ。具体使用了这 240 个中断源中的多少个,则由芯片制造商决定。由外设产生的中断信号,除了 SysTick的之外,全都连接到 NVIC 的中断输入信号线。典型情况下,处理器一般支持 16 到 32 个中断。

类型编号为 1-15 的系统异常,从 16 开始是外部中断类型。
三、向量表

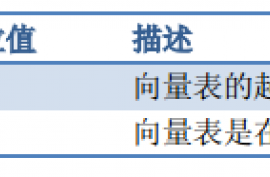
因为地址 0 处应该存储引导代码,所以它通常映射到 Flash或者是 ROM 器件,并且它们的值不得在运行时改变。然而,为了支持动态重分发中断, CM3 允许向量表重定位——从其它地址处开始定位各异常向量。这些地址对应的区域可以是代码区,但更多是在 RAM 区。在 RAM 区就可以修改向量的入口地址了。为了实现这个功能, NVIC中有一个寄存器,称为“向量表偏移量寄存器”(在地址 0xE000_ED08处),通过修改它的值就能重定位向量表。
向量表偏移量寄存器(VTOR)(地址:0xE000_ED08)

作者:血染风采2016
文章来源:CSDN(版权归著作者所有)