作者:linuxer
一、前言
上一节主要描述了为了打开MMU而进行的Translation table的建立,本文延续之前的话题,主要是进行CPU的初始化(注:该初始化仅仅为是为了turn on MMU)。
本文主要分析ARM64初始化过程中的__cpu_setup函数,代码位于arch/arm64/mm/proc.S中。主要的内容包括:
1、cache和TLB的处理
2、Memory attributes lookup table的构建
3、SCTLR_EL1、TCR_EL1的设定
二、cache和TLB的处理
1、oerview
根据ARM64 boot protocol,我们知道,会bootloader将内核解压并copy到RAM中,同时将CPU core(BSP)的状态设定为:关闭MMU,disable D-cache,I-cache状态可以是enable,也可以是disable的。其实在bootloader将控制权交给Kernel之前,bootloader已经走过千山万水,为了性能,很可能是打开了MMU以及各种cache,只是在进入kernel的时候,受限于ARM64 boot protocol而将CPU以及cache、MMU等硬件状态设定为指定的状态。因此,实际上这时候,instruction cache以及TLB中很可能有残留的数据,因此需要将其清除。
2、如何清除instruction cache的数据?
听起来这个问题似乎有点愚蠢,实际上不是。随着人类不断向更快的计算机系统进发,memory hierarchy也变得异常复杂起来,cache也形成了cache hierarchy(ARMv8最大支持7个level,L1~L7),不同级别的cache中都包含了部分下一级cache(或者main memory)的内容。这时候,维护数据一致性变得复杂了,例如:当要操作(例如clean或者invalidate)某个地址对应的cacheline的时候,是仅仅操作L1还是覆盖L1和L2,异或将L1~L3中对应的cacheline都设置为无效呢?PoU(Point of Unification)和PoC(Point of Coherency)这两个术语就是用来定义cache操作范围的,它们其实都是用来描述计算机系统中memory hierarchy的一个具体的“点”,操作范围是从PE到该点的所有的memory level。
我们先看PoU,PoU是以一个特定的PE(该PE执行了cache相关的指令)为视角。PE需要透过各级cache(涉及instruction cache、data cache和translation table walk)来访问main memory,这些操作在memory hierarchy的某个点上(或者说某个level上)会访问同一个copy,那么这个点就是该PE的Point of Unification。假设一个4核cpu,每个core都有自己的L1 instruction cache和L1 Data cache,所有的core共享L2 cache。在这样的一个系统中,PoU就是L2 cache,只有在该点上,特定PE的instruction cache、data cache和translation table walk硬件单元访问memory的时候看到的是同一个copy。
PoC可以认为是Point of System,它和PoU的概念类似,只不过PoC是以系统中所有的agent(bus master,又叫做observer,包括CPU、DMA engine等)为视角,这些agents在进行memory access的时候看到的是同一个copy的那个“点”。例如上一段文章中的4核cpu例子,如果系统中还有一个DMA controller和main memory(DRAM)通过bus连接起来,在这样的一个系统中,PoC就是main memory这个level,因为DMA controller不通过cache访问memory,因此看到同一个copy的位置只能是main memory了。
之所以区分PoC和PoU,根本原因是为了更好的利用cache中的数据,提高性能。OK,我们回到本节开始的问题:如何清除instruction cache的数据?我们还是用一个具体的例子来描述好了:对于一个PoU是L2 cache的系统,清除操作应该到哪一个level?根据ARM64 boot protocol规定,kernel image对应的VA会被cleaned to PoC,这时候,各级的data cache的数据都是一致性的,按理说,BSP只需要清除本cpu core上的instruction cache就OK了。不过代码使用了PoU,也就是说操作到了L2,而实际上,L2是unified cache,其数据是有效的,清除了会影响性能,这里我也想的不是很清楚,先存疑吧。
3、代码解析
ENTRY(__cpu_setup)
ic iallu --------------------------------(1)
tlbi vmalle1is------------------------------(2)
dsb ish --------------------------------(3)
mov x0, #3 << 20 ----------------------------(4)
msr cpacr_el1, x0 // Enable FP/ASIMD
msr mdscr_el1, xzr // Reset mdscr_el1
(1)ic iallu指令设置instruction cache中的所有的cache line是无效的,直到PoU。同时设置为无效状态的还包括BTB(Branch Target Buffer) cache。在处理器设计中,分支指令对性能的影响非常巨大(打破了pipeline,影响了并行处理),因此在处理器中会设定一个Branch target predictor单元用来对分支指令进行预测。Branch target predictor凭什么进行预测呢?所谓预测当然是根据过去推测现在,因此,硬件会记录分支指令指令的跳转信息,以便Branch target predictor对分支指令进行预测,这个硬件单元叫做Branch Target Buffer。程序中的分支指令辣么多,Branch Target Buffer不可能保存所有,只能cache近期使用到的分支跳转信息。
(2)tlbi这条指令通过猜测也知道是对TLB进行invalidation的操作,但是vmalle1is是什么鬼?它其实是vm-all-e1-is,vmall表示要invalidate all TLB entry,e1表示该操作适用于EL1,is表示inner sharebility。根据ARM ARM描述,这条指令的作用范围是inner shareable的所有PEs。这里有一个疑问:其实启动过程有些是只在BSP上进行,例如前面文章中的save boot parameter、校验blob、建立页表都是全局性的,只做一次就OK了。而这里的__cpu_setup函数是会在每一个cpu core上执行,因此应该尽量少的影响系统。如果这里是invalidation所有的inner shareable的PE的TLB,那么在secondary cpu core启动的时候会再执行一次,对系统影响很大,合理的操作应该是操作自己的TLB就OK了。
(3)step 1和step 2的操作和打开MMU操作有严格的时序要求,dsb这个memory barrier操作可以保证在执行打开MMU的时候,step 1和step 2都已经执行完毕。同样的,ish表示inner shareable。
(4)CPACR_EL1(Architectural Feature Access Control Register)是用来控制Trace,浮点运算单元以及SIMD单元的。FPEN,bits [21:20]是用来控制EL0和EL1状态的时候访问浮点单元和SIMD单元是否会产生exception从进入上一个exception level。这里的设定运行用户空间(EL0)和内核空间(EL1)访问浮点单元和SIMD单元。MDSCR_EL1(Monitor Debug System Control Register)主要用来控制debug系统的。
三、Memory attributes lookup table的构建
1、overview
MMU的作用有三个:地址映射,控制memory的访问权限,控制memory attribute。ARM64的启动过程之(二):创建启动阶段的页表对前面两个功能有了简单的描述,关于memory attribute将在本节描述。在Translation table中描述符中除了地址信息还有一些attribute的信息,例如attribute index域,既然叫做index则说明该域并没有保存实际的memory attribute,实际的attribute保存在MAIR_ELx中。在这个64 bit的寄存器中,每8个bit一组,形成一种类型的memory attribute。
2、memory type
我们知道,ARMv8采用了weakly-order内存模型,也就是说,通俗的讲就是处理器实际对内存访问(load and store)的执行序列和program order不一定保持严格的一致,处理器可以对内存访问进行reorder。例如:对于写操作,processor可能会合并两个写的请求。处理器这么任性当然是从性能考虑,不过这大大加大了软件的复杂度(软件工程师需要理解各种memory barrier操作,例如ISB/DSB/DMB,以便控制自己程序的内存访问的order)。
地址空间那么大,是否都任由processor胡作非为呢?当然不是,例如对于外设的IO地址,处理必须要保持其order。因此memory被分成两个基本的类型:normal memory和devicememory。除了基本的memory type,还有memory attribute(例如:cacheability,shareability)来进一步进行描述,我们在下一节描述。
标识为normal memory type的memory就是我们常说的内存而已,对其访问没有副作用(side effect),也就是说第n次和第n+1次访问没有什么差别。device memory就不会这样,对一些状态寄存器有可能会read clear,因此n和n+1的内存访问结果是不一样的。正因为如此,processor可以对这些内存操作进行reorder、repeat或者merge。我们可以把程序代码和数据所在的memory设定为normal memory type,这样可以获取更高的性能。例如,在代码执行过程中,processor可能进行分支预测,从而提前加载某些代码进入pipeline(而实际上,program不一定会fetch那些指令),如果设定了不正确的memory type,那么会阻止processor进行reorder的动作,从而阻止了分支预测,进而影响性能。
对于那些外设使用的IO memory,对其的访问是有side effect的,很简单的例子就是设备的FIFO,其地址是固定不变的,但是每次访问,内部的移位寄存器就会将下一个数据移出来,因此每次访问同一个地址实际上返回的数据是不一样的。device不存在cache的设定,总是no cache的,处理器访问device memory的时候,限制会比普通memory多,例如不能进行Speculative data accesses(所谓不能进行Speculative data accesses就是说cpu对memory的访问必须由顺序执行的执行产生,不能由于自己想加快性能而投机的,提前进行某些数据访问)。
3、 memory attribute
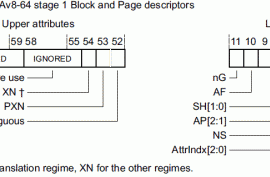
上一节将memory分成两个大类:normal memory和device,但是这么分似乎有些粗糙,我们可以进一步通过memory attribute将memory分成更多的区域。一个memory range对应的memory attribute是定义在页表的描述符中(由upper attribues和lower attributes组成),最重要的attributes定义在lower attributes中的AttrIndx[2:0],该域只是一个index而已,指向MAIR_ELx中具体的memory attribute。8-bit的memory attribute的具体解释可以参考ARM ARM。
对于device type,其总是non cacheable的,而且是outer shareable,因此它的attribute不多,主要有下面几种附加的特性:
(1)Gathering 或者non Gathering (G or nG)。这个特性表示对多个memory的访问是否可以合并,如果是nG,表示处理器必须严格按照代码中内存访问来进行,不能把两次访问合并成一次。例如:代码中有2次对同样的一个地址的读访问,那么处理器必须严格进行两次read transaction。
(2)Re-ordering (R or nR)。这个特性用来表示是否允许处理器对内存访问指令进行重排。nR表示必须严格执行program order。
(3)Early Write Acknowledgement (E or nE)。PE访问memory是有问有答的(更专业的术语叫做transaction),对于write而言,PE需要write ack操作以便确定完成一个write transaction。为了加快写的速度,系统的中间环节可能会设定一些write buffer。nE表示写操作的ack必须来自最终的目的地而不是中间的write buffer。
对于normal memory,可以是non-cacheable的,也可以是cacheable的,这样就需要进一步了解Cacheable和shareable atrribute,具体如下:
(1)是否cacheable
(2)write through or write back
(3)Read allocate or write allocate
(4)transient or non-transient cache
最后一点要说明的是由于cache hierararchy的存在,memory的属性可以针对inner和outer cache分别设定,具体如何区分inner和outer cache是和具体实现相关,但通俗的讲,build in在processor内的cache是inner的,而outer cache是processor通过bus访问的。
4、代码分析
ldr x5, =MAIR(0x00, MT_DEVICE_nGnRnE) | \
MAIR(0x04, MT_DEVICE_nGnRE) | \
MAIR(0x0c, MT_DEVICE_GRE) | \
MAIR(0x44, MT_NORMAL_NC) | \
MAIR(0xff, MT_NORMAL)
msr mair_el1, x5
页表中的memory attribute的信息并非直接体现在descriptor中的bit中,而是通过了一个间接的手段。描述符中的AttrIndx[2:0]是一个index,可以定位到8个条目,而这些条目就是保存在MAIR_EL1(Memory Attribute Indirection Register (EL1))中。对于ARM64处理器,linux kernel定义了下面的index:
#define MT_DEVICE_nGnRnE 0
#define MT_DEVICE_nGnRE 1
#define MT_DEVICE_GRE 2
#define MT_NORMAL_NC 3
#define MT_NORMAL 4
NC是no cache,也就是说MT_NORMAL_NC的memory是normal memory,但是对于这种类型的memory的访问不需要通过cache系统。这些index用于页表中的描述符中关于memory attribute的设定,对于初始化阶段的页表都是被设定成MT_NORMAL。
四、SCTLR_EL1、TCR_EL1的设定
1、寄存器介绍
SCTLR_EL1是一个对整个系统(包括memory system)进行控制的寄存器,我们这里描述几个重要的域。这些域有两种类型,一种是控制EL0状态时候能访问的资源。例如:UCI bit[26]控制是否允许EL0执行cache maintemance的指令(DC或者IC指令),如果不允许,那么会陷入EL1。nTWE bit[18]控制是否允许EL0执行WFE指令,如果不允许,那么会陷入EL1。bit 16类似bit 18,但是是for WFI指令的。UCT bit[15]控制是否允许EL0访问CTR_EL0(该寄存器保存了cache信息),如果不允许,那么会陷入EL1。UMA,bit [9]控制是否可以访问cpu状态寄存器的PSTATE.{D,A, I, F}比特。还有一种是实际控制memory system的域,例如:C bit[2]是用来enable或者disable EL0 & EL1 的data cache。具体包括通过stage 1 translation table访问的memory以及对stage 1 translation table自身memory的访问。I bit[12]是用来enable或者disable EL0 & EL1 的instruction cache。M bit[0]是用来enable或者disable EL0 & EL1 的MMU。
我们知道,kernel space和user space使用不同的页表,因此有两个Translation Table Base Registers,形成两套地址翻译系统,TCR_EL1寄存器主要用来控制这两套地址翻译系统。TBI1,bit[38]和TBI0,bit[37]用来控制是否忽略地址的高8位(TBI就是Top Byte ignored的意思),如果允许忽略地址的高8位,那么MMU的硬件在进行地址比对,匹配的时候忽略高八位,这样软件可以自由的使用这个byte,例如对于一个指向动态分配内存的对象指针,可以通过高8位来表示reference counter,从而可以跟踪其使用情况,reference count等于0的时候,可以释放内存。AS bit[36]用来定义ASID(address space ID)的size,A1, bit [22]用来控制是kernel space还是user space使用ASID。ASID是和TLB操作相关,一般而言,地址翻译的时候并不是直接查找页表,而是先看TLB是否命中,具体判断的标准是虚拟地址+ASID,ASID是每一个进程分配一个,标识自己的进程地址空间。这样在切换进程的时候不需要flush TLB,从而有助于performance。TG1,bits [31:30]和TG0,bits [15:14]是用来控制page size的,可以是4K,16K或者64K。当MMU进行地址翻译的时候需要访问页表,SH1, bits [29:28]和SH0, bits [13:12]是用来控制页表所在memory的Shareability attribute。ORGN1, bits [27:26]和ORGN0, bits [11:10]用来控制页表所在memory的outercachebility attribute的。IRGN1, bits [25:24]和IRGN0, bits [9:8]用来控制页表所在memory的inner cachebility attribute的。T1SZ, bits [21:16]和T0SZ, bits [5:0]定义了虚拟地址的宽度。
2、代码分析
代码位于arch/arm64/mm/proc.S中,该函数主要为打开MMU做准备,具体代码如下:
adr x5, crval ------------------------------(1)
ldp w5, w6, [x5]
mrs x0, sctlr_el1
bic x0, x0, x5 // clear bits
orr x0, x0, x6 // set bits
ldr x10, =TCR_TxSZ(VA_BITS) | TCR_CACHE_FLAGS | TCR_SMP_FLAGS | \
TCR_TG_FLAGS | TCR_ASID16 | TCR_TBI0
tcr_set_idmap_t0sz x10, x9 -----------------------(2)
mrs x9, ID_AA64MMFR0_EL1
bfi x10, x9, #32, #3
msr tcr_el1, x10 ----------------------------(3)
ret // return to head.S ---------------------(4)
ENDPROC(__cpu_setup)
(1)在调用__enable_mmu之前要准备好SCTLR_EL1的值,该值在这段代码中设定并保存在x0寄存器中,随后做为参数传递给__enable_mmu函数。具体怎么设定SCTLR_EL1的值呢?这是通过crval变量设定的,如下:
.type crval, #object
crval:
.word 0xfcffffff----------------SCTLR_EL1寄存器中需要清0的bit
.word 0x34d5d91d -------------SCTLR_EL1寄存器中需要设置成1的bit
由代码可知,EE和E0E这两个bit没有清零,因此实际上这些bit保持不变(在el2_setup中已经设定)。这里面具体各个bit的含义清参考ARM ARM文档,我们不一一说明了。
(2)这里的代码是准备TCR寄存器的值。TCR_TxSZ(VA_BITS)是根据CONFIG_ARM64_VA_BITS配置来设定内核和用户空间的size,其他的是进行page size的设定或者是page table对应的memory的attribute的设定,具体可以对照ARM ARM文档进行分析。
(3)到这里x10已经准备好了TCR寄存器的值,还缺省IPS(Intermediate Physical Address Size)的设定(IPS和2 stage地址映射相关,它和虚拟化有关,这里就不展开描述了,内容太多)。ID_AA64MMFR0_EL1, AArch64 Memory Model Feature Register 0,该寄存器保存了memory model和memory management的支持情况,该寄存器的PARange保存了物理地址的宽度信息,bfi x10, x9, #32, #3 指令就是将x9寄存器的内容左移32bit,copy 3个bit到x10寄存器中(IPS占据bits [34:32])。
(4)stext的代码如下:
ENTRY(stext)
……
ldr x27, =__mmap_switched
adr_l lr, __enable_mmu
b __cpu_setup
ENDPROC(stext)
在调用__cpu_setup之前设定了lr的内容是__enable_mmu,而调用__cpu_setup使用的是b而不是bl指令,因此lr寄存器没有修改,因此,这里的ret返回到__enable_mmu函数。
文章来源:蜗窝科技