处理器,也被称为中央处理器(Central Processing Unit,CPU),是计算机系统中的关键组件之一,负责执行计算机程序中的指令,控制计算机的各个部分,并处理数据。
处理器


未来产品阵容包括采用先进小芯片封装(Chiplet)集成技术的R-Car SoC和基于Arm®核的车用MCU
11 月 7 日 - 全球半导体解决方案供应商瑞萨电子(TSE:6723)今日公开了针对汽车领域所有主要应用的下一代片上系统(SoC)和微控制器(MCU)计划。

瑞萨公开下一代车用SoC和MCU处理器产品路线图

瑞萨第五代R-Car产品家族
瑞萨预先公布了第五代R-Car SoC的相关信息,该SoC面向高性能应用,采用先进的Chiplet小芯片封装集成技术,将为车辆工程师在设计时带来更大的灵活度。举例来说,若高级驾驶辅助系统(ADAS)需要兼顾更突出的AI性能时,工程师可将AI加速器集成至单个芯片中。
瑞萨还分享了即将推出的下一代R-Car产品家族两款MCU产品规划:一款为全新跨界MCU系列,旨在为下一代汽车E/E架构中的域和区域电子控制单元(ECU)打造所需的高性能,这款产品将缩小传统MCU与先进R-Car SoC间的性能差距;瑞萨同时还将发布一款为车辆控制应用量身定制的独立MCU平台。这两款MCU都将采用Arm®架构,并将成为卓越的R-Car产品家族重要成员,为车辆工程师提供完善的可扩展选项和软件复用性。
作为产品路线图的一部分,瑞萨计划提供一个虚拟软件开发环境,配合汽车行业广为人知的“左移”模式。这些软件工具将允许客户在开发过程中更早地进行软件设计与测试。
Vivek Bhan, Senior Vice President, Co-General Manager of High Performance Computing, Analog and Power Solutions Group at Renesas表示:“基于与一级供应商和OEM客户多年的合作及讨论,瑞萨制定了这一路线图。我们收到最多的客户反馈是,需要在不影响质量的前提下加快开发速度。这意味着必须在拿到硬件之前启动软件设计和验证。因此,我们将继续投资“左移”模式和软件优先创新,部署新的可扩展嵌入式处理器,并加强瑞萨本已庞大的开发工具网络,助力客户实现目标。”
第五代R-Car SoC平台
直到第四代推出之前,R-Car SoC均针对特定案例而设计,例如需要高阶AI性能的ADAS/自动驾驶,以及具有增强通信功能的网关解决方案等。瑞萨的第五代R-Car SoC将采用Chiplet技术搭建一个灵活的平台,可根据不同案例的不同要求进行定制。新平台将提供从入门级到高端型号的多种处理器集,并可将AI加速器等各种IP,以及合作伙伴和客户的IP集成至单个封装。由此,将为用户带来根据自身需求定制设计的选择。
两款面向车辆控制应用的全新Arm内核MCU平台
随着汽车E/E架构的不断发展,域控制单元(DCU)和区域控制单元的高性能计算与实时处理能力变得愈发重要。瑞萨为应对这一挑战,开发了基于Arm核的32位跨界R-Car MCU平台,这一平台内置NVM(非易失性存储器),可提供比目前传统MCU更高的性能。此外,立足RH850产品家族MCU的卓越成就,瑞萨还推出同样采用Arm技术的全新R-Car MCU系列,以扩展其车辆控制产品阵容。这意味着车辆系统开发人员将首次能够借助Arm的软件和庞大生态系统,使用这些全新MCU来构建动力总成、车身控制、底盘和仪表盘系统。此次扩展将使瑞萨能够在MCU和SoC之间实现IP标准化,从而提升软件的可用性,降低客户开发费用。
瑞萨计划从2024年起,按照这一路线图陆续推出新产品。
软件开发环境
随着车载软件的规模和复杂性不断增加,使用硬件进行软件设计的传统模式因其冗长的生产流程而逐渐过时。瑞萨已率先推出应用软件虚拟开发环境,提供先进的调试与评估工具,用于分析和评估软件性能。从2024年一季度起,瑞萨将为下一代处理器提供这些工具。这样,开发人员甚至可以在下一代设备原型面世之前加速其软件开发工作,从而更快地将产品推向市场。
关于瑞萨电子
瑞萨电子(TSE: 6723),科技让生活更轻松,致力于打造更安全、更智能、可持续发展的未来。作为全球微控制器供应商,瑞萨电子融合了在嵌入式处理、模拟、电源及连接方面的专业知识,提供完整的半导体解决方案。成功产品组合加速汽车、工业、基础设施及物联网应用上市,赋能数十亿联网智能设备改善人们的工作和生活方式。更多信息,敬请访问renesas.com。关注瑞萨电子微信公众号,发现更多精彩内容。
Holtek深耕模拟信号处理器产品开发,宣布新推出HT82V39A三通道CIS模拟信号处理器。HT82V39A内建LED驱动器能赋予产品应用更多弹性,其模拟前端(AFE)采用3.3V作为主要电源,5V则为LED驱动器电源需求。针对中高速CIS传感器的应用,如中高阶的文件扫描仪、相片及多功能事务机等极为合适。

HT82V39A采用三个通道的结构,可提供一至三个通道的操作模式供使用者选择,A/D转换器采用16位的高分辨率设计,搭配40MSPS转换速率。整合3通道的LED驱动器,每通道最高可提供66mA的电流,各通道可通过3位的寄存器进行电流设置与调节,可节省系统空间的使用效率。封装上采用40-pin QFN。
Holtek拥有丰富的CIS传感器、数字及模拟电路设计开发经验,在扫描仪应用市场上已耕耘多年,将持续开发更高速且高整合性产品,提供更佳且更具竞争力的产品方案,以满足客户多样化的产品应用。
来源:Holtek
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。
如果你一直想要为嵌入式开发需求而构建一套基于 ARM 的工作站,那 Adlink 新推出的只有 200×160 毫米的一块微型 COM-HPC 小板,或许就能够满足你对于高性能服务器计算模块的需求。据悉,一家名为 Ampere Computing 的初创企业,长期致力于为数据中心应用开发基于 ARM 的定制芯片。但截至目前,x86 仍是该领域的首选。

即便如此,Ampere Computing 还是在两年前孤注一掷,将自家的 eMAG 处理器放到了一台工作站中,并通过 Avantek 进行销售。
然后快进到本周,我们又见到了来自 Adlink 的微型载板,特点是能够支持数量惊人的 ARM 内核与内存容量。

据悉,这也是该公司正准备上市的首批 COM-HPC 服务器类模块之一。该模块可用于构建多达 80 个 64-bit ARM Neoverse N1 内核的微型工作站。
这要归功于 Ampere 的 Altra SoC,它能够将 80 个 ARM 核心的频率推至 2.8GHz,且功耗仅为 175W 。

此外 COM-HPC Ampere Altra 支持六通道 @ 最高 768GB 的 DDR4 内存,辅以 64 条 PCIe 4.0 通道。如有需要,客户还能够选购 E-ATX 主板平台。
Adlink 表示,该产品及其开发套件符合 ARM 的嵌入式边缘可扩展开放架构(SOAFEE),可选 32 ~ 80 个 ARM v8.2(64-bit)核心,TDP 从 60 ~ 175W 不等。

除了用作车载原型设计的参考系统,Adlink 还提供了基于 ARM 服务器架构的软件开发应用的一套水冷原型系统。该公司嵌入式板卡与模块化产品经理 Alex Wang 在一份声明中解释道:“
通过与 Ampere 和 ARM 合作,并使用基于 Neoverse N1 的 Ampere Altra SoC,我们推出了具有极高的每瓦特性能表现的 COM-HPC Ampere Altra 架构。
对于战略合作伙伴与客户们来说,这将使得他们能够在边缘场景处理数据密集型的工作负载,而无需顾虑前期的大量投资、硬件过热、以及后续的维护成本。”
最后,Adlink 现已开始向合作伙伴寄送原型系统样品,同时开启了预订。不过截止发稿时,该公司尚未披露确切的定价和上市日期。
来源:cnBeta.COM




搭载全新Intel Xeon E-2300处理器及第三代Intel Xeon可扩展处理器的服务器系列,能为各种工作负载提供成本优化的企业级运算性能
Super Micro Computer,Inc. (SMCI) 为企业级运算、储存、网络解决方案和绿色计算技术等领域的全球领导者,宣布扩展其搭载全新Intel Xeon E-2300和第三代Intel Xeon可扩展处理器的单处理器系统产品组合。这些新系统将支持持续增长的垂直市场中的各种应用,助力客户实现配置优化,精确满足其从智能边缘应用入门级服务器到数据中心级系统等应用的不同需求。
MicroBlade和MicroCloud搭载Intel Xeon E-2300处理器,支持需要高密度运算基础架构的应用,包括内容串流、EDA、互动式游戏和裸机云端实例等。企业也能从搭载此全新处理器系列的机架式系统中获益,随着I/O和安全功能的增加,这些系统将成为设备和安全应用的理想选择。
搭载单处理器第三代Intel Xeon可扩展处理器的系统(如6U SuperBlade)为高密度多节点应用的理想选择。适用于电信环境的Supermicro E403壁挂式边缘服务器拥有更多的核心数、更大的内存容量和更快的I/O,提供高效能的同时保证了合适的性价比。
Supermicro总裁暨首席执行官Charles Liang表示:“我们的多节点解决方案和大容量机架式系统为企业和云提供商提供了全新的计算级别,帮助客户实现新一代的应用,从而达到优化的企业性能和TCO。我们不断扩充单处理器应用优化系统的产品组合,致力于为优化目标的工作负载提供上佳的效能和效率,用于包括电信、边缘、储存、安全、AI推理和裸机搭建。”
Supermicro最新单处理器系统拥有的效能和功能,能让数据中心支持不断扩大的工作负载组合,将数据中心等级的效能延伸到边缘。这些新系统采用PCI-E 4.0 I/O,与搭载前几代处理器的系统相比,可消除瓶颈并加快应用速度,且现在还支持Intel SGX安全功能。此外,新的单处理器系统有多种外形规格,包括多节点服务器、机架式服务器和工作站。
搭载单处理器第三代Intel Xeon可扩展处理器的系统支持最多16個DIMM插槽,可达最高4TB的DRAM或6TB的DRAM+Intel Optane 持久性内存(PMem),此内存容量在单处理器系统上是前所未有的。搭载Intel Xeon E-2300处理器的系统拥有最多8个核心和128GB DDR4内存,散热设计功率(TDP)为95瓦,能为小型企业提供不可或缺的服务器效能。

Supermicro服务器搭载第三代Intel Xeon可扩展处理器,专为单处理器应用优化,产品包含有:
-
SuperBlade–超高密度多节点系统
-
5G/Edge–可配置的移动网络和智能边缘应用的数据中心级运算
-
Mainstream–适合企业应用的多功能机架式服务器
-
WIO–I/O–优化的机架式服务器
-
Storage–专为企业优化的存储系统
此外,使用Intel Xeon E-2300的全新Supermicro服务器还包含:
-
MicroBlade–多功能且可扩展的多节点解决方案
-
MicroCloud–适合专用或可扩充云端托管的高密度系统
-
WIO–符合成本效益、通过I/O优化的机架式服务器
-
Mainstream–入门级企业机架式服务器
关于SuperMicroComputer,Inc.
Supermicro (SMCI), 为高性能、高效率服务器技术的领先创新者, 是全球企业数据中心、云计算、人工智能和边缘计算系统的高级服务器Building Block Solutions的主要提供商。 Supermicro致力于通过“We Keep IT Green”计划保护环境,并为客户提供市场上最节能、最环保的解决方案。
稿源:美通社
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。

2021年 8月 23日,在一年一度的 Hot Chips 大会上,IBM(纽交所证券代码:IBM)公布了即将推出的全新 IBM Telum 处理器的细节,该处理器旨在将深度学习推理能力引入企业工作负载,帮助实时解决欺诈问题。Telum 是 IBM 首款具有芯片上加速功能的处理器,能够在交易时进行 AI 推理。经过三年的研发,这款新型芯片上硬件加速技术实现了突破,旨在帮助客户从银行、金融、贸易和保险应用以及客户互动中大规模获得业务洞察。基于 Telum 的系统计划于 2022年上半年推出。

根据 IBM 委托 Morning Consult 开展的最近研究,90% 的受访者表示,必须做到无论数据位于何处,都能够构建和运行 AI 项目,这一点非常重要。[1]IBM Telum 旨在让应用能够在数据所在之处高效运行,帮助克服传统企业 AI 方法的限制 — 需要大量的内存和数据移动能力才能处理推理。借助 Telum,加速器在非常靠近任务关键型数据和应用的地方运行,这意味着企业可以对实时敏感交易进行海量推理,而无需在平台外调用 AI 解决方案,从而避免对性能产生影响。客户还可以在平台外构建和训练 AI 模型,在支持 Telum 的 IBM 系统上部署模型并执行推理,以供分析之用。
银行、金融、贸易、保险等领域的创新
如今,企业使用的检测方法通常只能发现已经发生的欺诈活动。由于目前技术的局限性,这一过程还可能非常耗时,并且需要大量计算,尤其是当欺诈分析和检测在远离任务关键型交易和数据的地方执行的情况下。由于延迟,复杂的欺诈检测往往无法实时完成 — 这意味着,在零售商意识到发生欺诈之前,恶意行为实施者可能已经用偷来的信用卡成功购买了商品。
根据 2020年的《消费者“前哨”网络数据手册》,2020年消费者报告的欺诈损失超过 33亿美元,高于 2019年的 18亿美元[2]。Telum 可帮助客户从欺诈检测态势转变为欺诈预防,从目前的捕获多个欺诈案例,转变为在交易完成前大规模预防欺诈的新时代,而且不会影响服务级别协议 (SLA)。
这款新型芯片采用了创新的集中式设计,支持客户充分利用 AI 处理器的全部能力,轻松处理特定于 AI 的工作负载;因此,它成为欺诈检测、贷款处理、贸易清算和结算、反洗钱以及风险分析等金融服务工作负载的理想之选。通过这些新型创新,客户能够增强基于规则的现有欺诈检测能力,或者使用机器学习,加快信贷审批流程,改善客户服务和盈利能力,发现可能失败的贸易或交易,并提出解决方案,以创建更高效的结算流程。


Telum 和 IBM 采用全栈方法进行芯片设计
Telum 遵循 IBM 在创新设计和工程方面的悠久传统,包括硬件和软件的共同创新,以及覆盖对半导体、系统、固件、操作系统和主要软件框架的有效整合。
该芯片包含 8个处理器核心,具有深度超标量乱序指令管道(A deep super-scalar out-of-order instruction pipeline),时钟频率超过 5GHz,并针对异构企业级工作负载的需求进行了优化。彻底重新设计的高速缓存和芯片互连基础架构为每个计算核心提供 32MB 缓存,可以扩展到 32个 Telum 芯片。双芯片模块设计包含 220亿个晶体管,17层金属层上的线路总长度达到 19英里。

半导体领先地位
Telum 是使用 IBM 研究院 AI 硬件中心的技术研发的首款 IBM 芯片。此外,三星是 IBM 在 7纳米 EUV 技术节点上研发的 Telum 处理器的技术研发合作伙伴。
Telum 是 IBM 在硬件技术领域保持领先地位的又一例证。作为世界上最大的工业研究机构之一,IBM 研究院最近宣布进军 2纳米节点,这是 IBM 芯片和半导体创新传统的最新标杆。在纽约州奥尔巴尼市 — IBM AI 硬件中心和奥尔巴尼纳米科技中心的所在地,IBM 研究院与公共/私营领域的行业参与者共同建立了领先的协作式生态系统,旨在推动半导体研究的进展,帮助解决全球制造需求,加速芯片行业的发展。
了解更多信息,请访问:
www.ibm.com/it-infrastructure/z/capabilities/real-time-analytics
关于 IBM 未来方向和意向的声明仅表示目标和目的,可能随时更改或撤销,恕不另行通知。
了解更多信息,请访问:www.ibm.com




贸泽电子 (Mouser Electronics) 即日起备货NXP Semiconductors的全新i.MX RT106S跨界处理器。这款处理器采用了Arm® Cortex®-M7内核的高级实现,可为嵌入式本地语音助手应用以及物联网、智能工业和智能家电应用提供所需的高CPU性能和实时响应能力。
贸泽分销的NXP i.MX RT106S处理器是EdgeVerse™边缘计算平台中的一款产品。该处理器的运行主频最高可达600MHz,具有1MB的片上SRAM,并支持面向GUI和增强型HMI应用的高级多媒体。i.MX RT106S处理器已获得运行一系列NXP整体式语音助手软件解决方案的授权,可为工程师提供多种功能和特性,例如基于音素的语音识别引擎。该处理器可实现低至20ns的实时低延迟响应,同时还拥有低功耗性能。
为了支持设计人员快速、轻松地在新产品设计中加入语音助手功能,贸泽还备货用于本地语音控制的NXP SLN-LOCAL2-IOT解决方案。该解决方案采用板载i.MX RT106S处理器和支持超过100个声控指令的自动语音识别引擎,可省去基于云的计算,为离线语音助手提供以隐私为优先的解决方案。SLN-LOCAL2-IOT解决方案提供了成本优化的参考设计和生产就绪的软件开发套件,可缩短上市时间并减少开发工作。
如需进一步了解i.MX RT106S处理器,敬请访问https://www.mouser.cn/new/nxp-semiconductors/nxp-imx-rt106s-crossover-processor/。
如需进一步了解适用于本地语音控制的SLN-LOCAL2-IOT解决方案,敬请访问https://www.mouser.cn/new/nxp-semiconductors/nxp-sln-local2-iot-development-kit/。
作为全球授权分销商,贸泽电子库存有丰富的半导体和电子元器件,并积极引入原厂新品,支持随时发货。贸泽旨在为客户供应全面认证的原厂产品,并提供全方位的制造商可追溯性。为帮助客户加速设计,贸泽网站提供了丰富的技术资源库,包括技术资源中心、产品数据手册、供应商特定参考设计、应用笔记、技术设计信息、设计工具以及其他有用的信息。
关于贸泽电子 (Mouser Electronics)
贸泽电子隶属于伯克希尔哈撒韦集团 (Berkshire Hathaway) 公司旗下,是一家授权电子元器件分销商,专门致力于向设计工程师和采购人员提供各产品线制造商的新产品。作为一家全球分销商,我们的网站mouser.cn能够提供多语言和多货币交易支持,分销超过1100家品牌制造商的500多万种产品。我们通过遍布全球的27个客户支持中心,为客户提供无时差的本地化贴心服务,并支持使用当地货币结算。更多信息,敬请访问: https://www.mouser.cn/。
今天分享一点之前在调试代码过程中遇到的知识点:关于__get_CONTROL的用法,及xQueueSend和xQueueSendFromISR的区别;
1、问题来源
我之前在FreeRTOS系统上移植了部分别人写的代码,移植前仔细看了下源码,确认没问题后,编译,下载,运行,突然“死机了”······
于是,我又再次确认了移植的代码,没有发现Bug所在。此时,我开启了在线调试功能,发现程序死在了“vPortEnterCritical”函数中的断言语句里。如下:

2、解决问题的过程
我解决问题还是按照常规思维,一步一步跟踪,很多问题其实都是类似道理,有规律可循。
1)查看configASSERT断言做了什么事?
跟踪代码:
#define configASSERT( x ) if( ( x ) == 0 ) { taskDISABLE_INTERRUPTS(); for( ;; ); }其中,里面taskDISABLE_ INTERRUPTS();就是关中断的意思。紧跟着后面执行了for( ;; );
看到这里,我明白了一点,就是死在for( ;; );里面了。
2)进一步查找问题
我又开始了思考,为什么会执行到这里来呢? 为什么会执行:
portDISABLE_INTERRUPTS(); uxCriticalNesting++; if( uxCriticalNesting == 1 )
这些语句呢?
这就是我们常说的“临界段”,这一点我学习RTOS的时候已经明白了,这一个函数肯定会被调用。于是,我把目标锁定了portNVIC_INT_CTRL_REG这个参数:
#define portNVIC_INT_CTRL_REG ( * ( ( volatile uint32_t * ) 0xe000ed04 ) )
0xe000ed04? 这个地址,相信之前了解过NVIC的都知道,就是Interrupt control state register.即中断控制状态寄存器。
3)确定问题点
从上面的分析,其实问题都已经浮现出来了。于是查看了【Cortex-M3权威指南】中相关的内容。(PS:这本手册真的能解决很多问题,翻译成中文,对大部分朋友来说是一件好事)
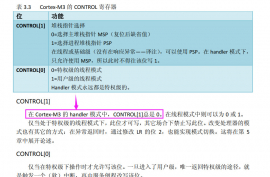
其实,有这个一个寄存器:控制寄存器(CONTROL),里面讲述的非常清楚:

看上图,大概意思就是:在中断模式下,CONTROL[1]为0。于是,又把思路转向了core_cm3.c文件中的源码:
__ASM uint32_t __get_CONTROL(void)
{
mrs r0, control
bx lr
}懂一点汇编的,相信在这里都已经明白,大概意思就是过去控制寄存器状态,这也是我开篇说的,让大家了解的__get_CONTROL。
4)在线调试,分析结论
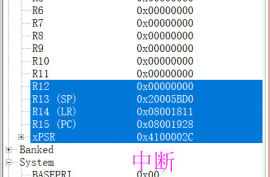
上面分析出来控制寄存器CONTROL,那么我们需要验证是否符合我们预期的效果,通过在线调试,断电就可得出,如下面两图:
a.在非中断情况下的值0x02
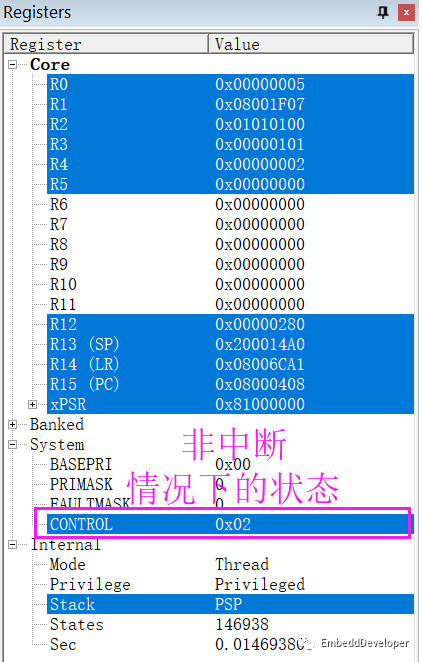
b.在中断情况下的值0x00
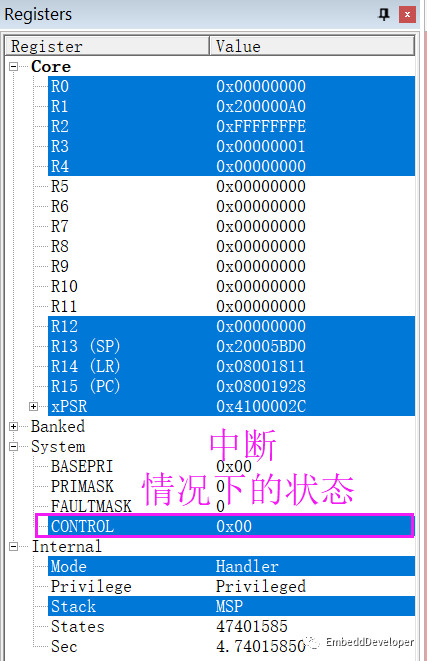
至此,问题已经查明就是CONTROL。
3、get_CONTROL的应用
一般在RTOS实时操作系统中,常常使用队列来处理我们的数据,也就是常说的FIFO(先入先出)。
比如:我们在FreeRTOS系统中,要将UART发送、或者接收的数据加入队列:在中断里加入队列,在非中断里加入队列。这个时候,就需要使用get_CONTROL来判断当前是否处于中断函数里。
当然,类似的情况很多,像CAN、I2C、SPI等一样的道理。
举例,CAN总线发送数据加入队列:

以上就是今天的内容,希望对你有所帮助。
来源:嵌入式专栏
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。


第 11 代英特尔®处理器的 Express-TL 模块是高性能要求的嵌入式和工业应用的理想选择
-
凌华科技的 Express-TL COM Express Type 6模块采用第 11 代 英特尔® Core™、Xeon® W 和 Celeron® 6000 处理器,最高可达8 核和 128 GB 内存
-
为首款支持 PCI Express Gen 4 x16 的 COM Express 模块,相较前一代Express-TL 有效提升两倍的带宽
-
专为恶劣工作环境温度而设计,支持-40°C 至 85°C,可以在工业环境中 24/7 全天候运行,服务长达 10 年
凌华科技推出全新首款 Express-TL COM Express Type 6 模块,该模块具有英特尔® Core™、Xeon® W 和 Celeron® 6000处理器和八核性能。包含英特尔® UHD Graphics和英特尔® AVX-512 VNNI 提供卓越的人工智能推理。 Express-TL 非常适合图像处理和分析、高速影像编码和串流媒体、医疗超声波、流量分析预测和其他要求苛刻的应用。

凌华科技模块产品中心资深产品经理王俊杰表示:“搭载英特尔®第 11 代处理器的 Express-TL 对高性能计算来说是一大助力。它展现了出色的系统性能和反应能力,非常适合那些依赖高度计算和大量使用的应用设置。”
主要功能包括:
-
英特尔® UHD Graphics核心支持四个 4K 独立显示器或一个8K 独立显示器,包括HDMI、DisplayPort端口、LVDS、嵌入式 DisplayPort端口和传统 VGA显示。
-
Express-TL 模块提供2.5 GbE 以太网和4 个USB 3.2 Gen 2 接口,允许10+ Gb/s 的传输速率。
-
英特尔 时间协调计算 (TCC) 与时效性网络 (TSN) 以太网控制器相结合,使工业 4.0 工厂在实现更智能、敏捷和更自主化之下能持续稳健可靠的运作。
-
额外的8C在25瓦TDP具备ECC内存功能和载板NVMe储存,特别适合有限空间的应用。
人工智能、机器学习和物联网设备的增长,连带影响从边缘到云端的实时处理需求。 Express-TL 模块提供进阶调整控制、沉浸式图形和出色的连接性,为人工智能、工作负载整合和其他密集计算需求提供了新的机会。
凌华科技的 Express-TL COM Express Type 6 模块与英特尔密切合作,使其具有抗震性、宽温设计和可靠的性能,有助于缩短开发周期并降低成本。工业系统整合商、经销商、工程师和其他应用开发者可体验 Express-TL 为功率受限的应用带来令人振奋的性能。
凌华科技过去在PCI 工业计算机制造商集团(PICMG)处于领导地位,以及作为开发开放标准(如 COM Express® 规范)的驱动推手,确实发挥着关键作用。凭借这些领导地位、权威和技术专长为客户提供开发载板所需的工具。
【关于凌华科技】
凌华科技(股票代号:6166)引领边缘计算,是AI人工智能驱动世界的推动者。我们制造并开发用于嵌入式、分布式与智能计算的边缘硬件与软件解决方案,全球超过1600家客户信任凌华科技,选择我们作为其关键任务的重要伙伴,从重症监护室的医疗计算机到全球第一辆高速自动驾驶赛车,都有我们的足迹。
凌华科技是英特尔、NVIDIA、AWS和SAS的重要合作伙伴,并加入了英特尔顾问委员会、ROS 2技术指导委员会以及Autoware自动驾驶开源基金会。我们积极参与了开源技术、机器人、自主化、物联网、5G等超过24个标准规范的制定,以驱动智能制造、网络通信、智能医疗、能源、国防军工、智能交通与信息娱乐等领域的创新。
凌华科技拥有1800多名员工和200多家合作伙伴。25年以来,我们秉持并推动当今和未来技术的发展,创新科技,转动世界。

近日,英特尔推出了全新一代英特尔®至强® W-3300 处理器,并将通过系统集成商进行发售。英特尔® 至强® W-3300 处理器通过智能化设计有效突破性能极限,其全新的处理器核心架构专为高级工作站用户打造,在单路解决方案中提供卓越的性能、扩展的平台功能,以及可媲美企业级的安全性和可靠性,让专业工作站用户可以在工作站上取得更好的工作成果。

重要意义:英特尔® 至强® W-3300 处理器专为多线程、I/O 密集型工作负载的新一代专业应用类软件而设计,可适用于人工智能、建筑、工程、施工以及影音娱乐等应用场景。英特尔® 至强® W-3300 处理器采用了可大幅提高效率的全新处理器核心架构,以及可支持数据完整性的先进技术,提供出色的工作站性能。
关于全新英特尔® 至强® W-3300 处理器:五款全新处理器(W-3375、W-3365、W-3345、W-3335 和 W-3323)在单路解决方案中,为用户提供出色的性能以及扩展的平台功能。它们提供最多38 个核心,并通过英特尔® 多线程技术支持最多 76 线程,频率最高可达 4.0 GHz!英特尔® 至强® W-3300 处理器拥有 64 个处理器 PCIe 4.0 通道,支持最高可达 4TB 的 DDR4-3200 纠错码(ECC)内存。
英特尔® 至强® W-3300 处理器采用全新处理器核心架构,代表着性能和效率进入新时代,与上一代处理器相比,拥有如下方面的提升:
-
Cinema 4D 负载的多线程性能提高达 45%[3]
-
AutoDesk Maya 中预览渲染负载提速达 26%[4]
-
Adobe Premiere Pro负载中的编辑和编码性能提速达 20%[5]
-
AutoDesk Maya 中的最终 3D 渲染负载提速达 27%[6]
其它特色技术包括:
-
采用英特尔® 睿频 2.0 技术,最高睿频可达 4.0 GHz
-
支持机器学习推理负载的英特尔® 深度学习加速技术
-
支持最高可达 4TB 的 DDR4-3200 8 通道内存
-
支持英特尔® 高级矢量扩展指令集 512
-
支持纠错码(ECC)内存
-
内置可靠性、可用性和可维护性(RAS)技术
-
支持英特尔® 傲腾™ 固态盘 P5800X
关于英特尔
英特尔(NASDAQ: INTC)作为行业引领者,创造改变世界的技术,推动全球进步并让生活丰富多彩。在摩尔定律的启迪下,我们不断致力于推进半导体设计与制造,帮助我们的客户应对最重大的挑战。通过将智能融入云、网络、边缘和各种计算设备,我们释放数据潜能,助力商业和社会变得更美好。如需了解英特尔创新的更多信息,请访问英特尔中国新闻中心newsroom.intel.cn以及官方网站intel.cn。
1、英特尔® 至强® W-3300 CPU:8个通道,4TB(2DPC) vs.英特尔® 至强® W-3200 CPU:6个通道1.5TB(2DPC)
2、英特尔® 至强® W-3300 CPU:8个通道,3200 MT/s(2DPC) vs. 英特尔® 至强® W-3200 CPU:6个通道2666 MT/s(2DPC)
3、基于英特尔®至强® W-3375处理器vs.英特尔®至强® W-3275处理器运行Cinebench R23多线程(MT)时的得分
4、基于英特尔® 至强® W-3375 处理器与英特尔® 至强® W-3275 处理器在运行 AutoDesk Maya 中的 Arnold 渲染器时的快速渲染时间。
5、基于英特尔® 至强® W-3375处理器vs. 英特尔® 至强® W-3275运行PugetBench(0.95.1) – Adobe Premiere Pro(2021) 15.0 – Standard时的得分。
6、基于英特尔® 至强® W-3375处理器vs.英特尔® 至强® W-3275处理器在运行 AutoDesk Maya 中的 Arnold 渲染器时的慢速渲染时间。



{kind=link}