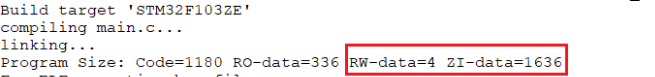学习STM32单片机的时候,总是能遇到“堆栈”这个概念。分享本文,希望对你理解堆栈有帮助。
对于了解一点汇编编程的人,就可以知道,堆栈是内存中一段连续的存储区域,用来保存一些临时数据。堆栈操作由PUSH、POP两条指令来完成。而程序内存可以分为几个区:
栈区(stack)
堆区(Heap)
全局区(static)
文字常亮区程序代码区
程序编译之后,全局变量,静态变量已经分配好内存空间,在函数运行时,程序需要为局部变量分配栈空间,当中断来时,也需要将函数指针入栈,保护现场,以便于中断处理完之后再回到之前执行的函数。
栈是从高到低分配,堆是从低到高分配。
普通单片机与STM32单片机中堆栈的区别
普通单片机启动时,不需要用bootloader将代码从ROM搬移到RAM。
但是STM32单片机需要。
这里我们可以先看看单片机程序执行的过程,单片机执行分三个步骤:
取指令
分析指令
执行指令
根据PC的值从程序存储器读出指令,送到指令寄存器。然后分析执行执行。这样单片机就从内部程序存储器去代码指令,从RAM存取相关数据。
RAM取数的速度是远高于ROM的,但是普通单片机因为本身运行频率不高,所以从ROM取指令慢并不影响。
而STM32的CPU运行的频率高,远大于从ROM读写的速度。所以需要用bootloader将代码从ROM搬移到RAM。
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
其实堆栈就是单片机中的一些存储单元,这些存储单元被指定保存一些特殊信息,比如地址(保护断点)和数据(保护现场)。
如果非要给他加几个特点的话那就是:
这些存储单元中的内容都是程序执行过程中被中断打断时,事故现场的一些相关参数。如果不保存这些参数,单片机执行完中断函数后就无法回到主程序继续执行了。
这些存储单元的地址被记在了一个叫做堆栈指针(SP)的地方。
结合STM32的开发讲述堆栈
从上面的描述可以看得出来,在代码中是如何占用堆和栈的。可能很多人还是无法理解,这里再结合STM32的开发过程中与堆栈相关的内容来进行讲述。
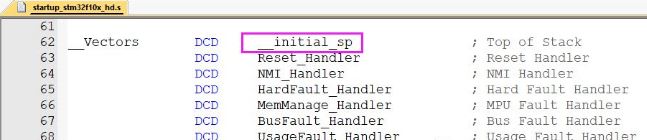
如何设置STM32的堆栈大小?
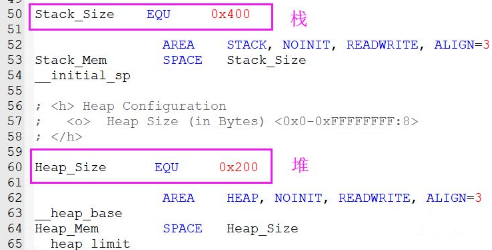
在基于MDK的启动文件开始,有一段汇编代码是分配堆栈大小的。

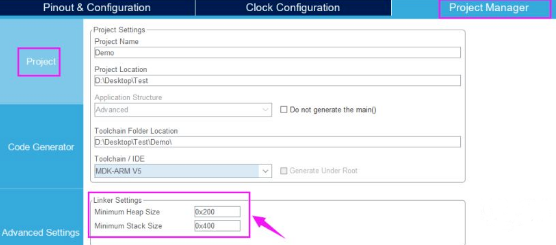
这里重点知道堆栈数值大小就行。还有一段AREA(区域),表示分配一段堆栈数据段。数值大小可以自己修改,也可以使用STM32CubeMX数值大小配置,如下图所示。

STM32F1默认设置值0x400,也就是1K大小。
Stack_Size EQU 0x400
函数体内局部变量:
void Fun(void){ char i; int Tmp[256]; //...}局部变量总共占用了256*4 + 1字节的栈空间。所以,在函数内有较多局部变量时,就需要注意是否超过我们配置的堆栈大小。
函数参数:
void HAL_GPIO_Init(GPIO_TypeDef *GPIOx, GPIO_InitTypeDef *GPIO_Init)
这里要强调一点:传递指针只占4字节,如果传递的是结构体,就会占用结构大小空间。提示:在函数嵌套,递归时,系统仍会占用栈空间。
堆(Heap)的默认设置0x200(512)字节。
Heap_Size EQU 0x200
大部分人应该很少使用malloc来分配堆空间。虽然堆上的数据只要程序员不释放空间就可以一直访问,但是,如果忘记了释放堆内存,那么将会造成内存泄漏,甚至致命的潜在错误。
MDK中RAM占用大小分析
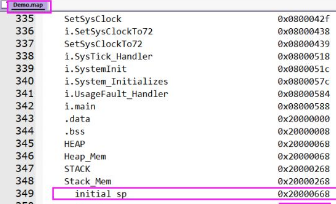
经常在线调试的人,可能会分析一些底层的内容。这里结合MDK-ARM来分析一下RAM占用大小的问题。在MDK编译之后,会有一段RAM大小信息:

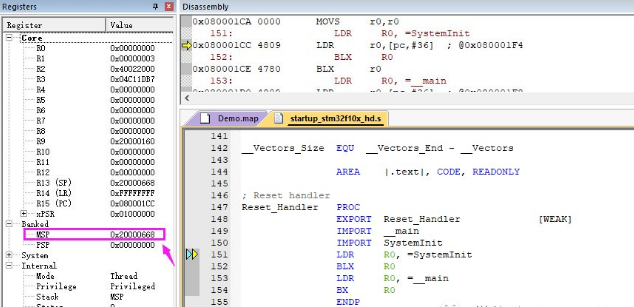
这里4+6=1640,转换成16进制就是0x668,在进行在调试时,会出现:

这个MSP就是主堆栈指针,一般我们复位之后指向的位置,复位指向的其实是栈顶:

而MSP指向地址0x20000668是0x20000000偏移0x668而得来。具体哪些地方占用了RAM,可以参看map文件中【Image Symbol Table】处的内容:

来源:嵌入式Linux
免责声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请联系小编进行处理(联系邮箱:cathy@eetrend.com)。