judy 在 提交

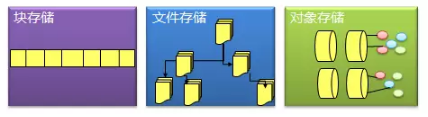
从应用角度看块存储、文件存储、对象存储
产品和市场需求有各种相互影响的关系,但不管是哪一种,最终呈现都是产品和应用需求需要对应匹配。应用需求越多样化,市场也就划分得更加细,产品种类也就更加丰富。在存储行业,我们也可以从“应用适配”这个角度来聊聊各类存储。
传统认知上来说,IT设备分为计算/存储/网络三大类,相互之间是有明显的楚河汉界的。计算大家都清楚,服务器,小型机,大型机;网络也就是路由器交换机;存储有内置存储和外置存储,最常见的就是磁盘阵列。在HCI(超融合)这个概念没被热炒之前,计算网络存储还都是泾渭分明,各担其责的。今天我们先不讨论超融合的情况,仅基于传统理解,看看存储的情况。
从逻辑上存储通常分为块存储,文件存储,对象存储。这三类存储在实际应用中的适配环境还是有着明显的不同的。
块存储(DAS/SAN)通常应用在某些专有的系统中,这类应用要求很高的随机读写性能和高可靠性,上面搭载的通常是Oracle/DB2这种传统数据库,连接通常是以FC光纤(8Gb/16Gb)为主,走光纤协议。如果要求稍低一些,也会出现基于千兆/万兆以太网的连接方式,MySQL这种数据库就可能会使用IP SAN,走iSCSI协议。通常使用块存储的都是系统而非用户,并发访问不会很多,经常出现一套存储只服务一个应用系统,例如如交易系统,计费系统。典型行业如金融,制造,能源,电信等。
文件存储(NAS)相对来说就更能兼顾多个应用和更多用户访问,同时提供方便的数据共享手段。毕竟大部分的用户数据都是以文件的形式存放,在PC时代,数据共享也大多是用文件的形式,比如常见的的FTP服务,NFS服务,Samba共享这些都是属于典型的文件存储。几十个用户甚至上百用户的文件存储共享访问都可以用NAS存储加以解决。在中小企业市场,一两台NAS存储设备就能支撑整个IT部门了。CRM系统,SCM系统,OA系统,邮件系统都可以使用NAS存储统统搞定。甚至在公有云发展的早几年,用户规模没有上来时,云存储的底层硬件也有用几套NAS存储设备就解决的,甚至云主机的镜像也有放在NAS存储上的例子。文件存储的广泛兼容性和易用性,是这类存储的突出特点。但是从性能上来看,相对SAN就要低一些。NAS存储基本上是以太网访问模式,普通千兆网,走NFS/CIFS协议。
对象存储概念出现得晚一些,存储标准化组织SINA早在2004年就给出了定义,但早期多出现在超大规模系统,所以并不为大众所熟知,相关产品一直也不温不火。一直到云计算和大数据的概念全民强推,才慢慢进入公众视野。
前面说到的块存储和文件存储,基本上都还是在专有的局域网络内部使用,而对象存储的优势场景却是互联网或者公网,主要解决海量数据,海量并发访问的需求。基于互联网的应用才是对象存储的主要适配(当然这个条件同样适用于云计算,基于互联网的应用最容易迁移到云上,因为没出现云这个名词之前,他们已经在上面了),基本所有成熟的公有云都提供了对象存储产品,不管是国内还是国外。
对象存储常见的适配应用如网盘、媒体娱乐,医疗PACS,气象,归档等数据量超大而又相对“冷数据”和非在线处理的应用类型。这类应用单个数据大,总量也大,适合对象存储海量和易扩展的特点。网盘类应用也差不多,数据总量很大,另外还有并发访问量也大,支持10万级用户访问这种需求就值得单列一个项目了(这方面的扫盲可以想想12306)。归档类应用只是数据量大的冷数据,并发访问的需求倒是不太突出。
另外基于移动端的一些新兴应用也是适合的,智能手机和移动互联网普及的情况下,所谓UGD(用户产生的数据,手机的照片视频)总量和用户数都是很大挑战。毕竟直接使用HTTP get/put就能直接实现数据存取,对移动应用来说还是有一定吸引力的。
对象存储的访问通常是在互联网,走HTTP协议,性能方面,单独看一个连接的是不高的(还要解决掉线断点续传之类的可靠性问题),主要强大的地方是支持的并发数量,聚合起来的性能带宽就非常可观了。

从产品形态上来看,块存储和文件存储都是成熟产品,各种规格形态的硬件已经是琳琅满目了。但是对象存储通常你看到都是一堆服务器或者增强型服务器,毕竟这东西现在还是互联网行业用得多点,DIY风格。
关于性能容量等方面,我做了个图,对三种存储做直观对比。

块存储就像超跑,根本不在意能不能多载几个人,要的就是极限速度和高速下的稳定性和可靠性,各大厂商出新产品都要去纽北赛道刷个单圈最快纪录,千方百计就为提高一两秒,跑不进7分以内都看不到前三名。(块存储容量也不大,TB这个数量级,支持的应用和适用的环境也比较专业(FC+Oracle),在乎的都是IOPS的性能值,厂商出新产品也都想去刷个SPC-1,测得好的得意洋洋,测得不好自动忽略。)
文件存储像集卡,普适各种场合,又能装数据(数百TB),而且兼容性好,只要你是文件,各种货物都能往里塞,在不超过性能载荷的前提下,能拉动常见的各种系统。标准POXIS接口,后车门打开就能装卸。卡车也不挑路,不像块存储非要上赛道才能开,普通的千兆公路就能畅通无阻。速度虽然没有块存储超跑那么块,但跑个80/100码还是稳稳当当.
而对象存储就像海运货轮,应对的是"真·海量",几十上百PB的数据,以集装箱/container(桶/bucket)为单位码得整整齐齐,里面装满各种对象数据,十万客户发的货(数据),一条船就都处理得过来,按照键值(KeyVaule)记得清清楚楚。海运速度慢是慢点,有时候遇到点网络风暴还不稳定,但支持断点续传,最终还是能安全送达的,对大宗货物尤其是非结构化数据,整体上来看是最快捷便利的。
从访问方式来说,块存储通常都是通过光纤网络连接,服务器/小机上配置FC光纤HBA卡,通过光纤交换机连接存储(IP SAN可以通过千兆以太网,以iSCSI客户端连接存储),主机端以逻辑卷(Volume)的方式访问。连接成功后,应用访问存储是按起始地址,偏移量Offset的方法来访问的。
而NAS文件存储通常只要是局域网内,千兆/百兆的以太网环境皆可。网线连上,服务器端通过操作系统内置的NAS客户端,如NFS/CIFS/FTP客户端挂载存储成为一个本地的文件夹后访问,只要符合POXIS标准,应用就可以用标准的open,seek, write/read,close这些方法对其访问操作。
对象存储不在乎网络,而且它的访问比较有特色,只能存取删(put/get/delete),不能打开修改存盘。只能取下来改好后上传,去覆盖原对象。(因为中间是不可靠的互联网啊,不能保证你在修改时候不掉线啊。所谓你在这头,对象在那头,所爱对象隔山海,山海不可平。)
另外再说一点分布式存储的问题,以上三种存储都可以和分布式概念结合,成为分布式文件系统,分布式块存储,还有天生分布式的对象存储。
对象存储的定义就把元数据管理和数据存储访问分开在不同的节点上,多个节点应对多并发的访问,这自然就是一个分布式的存储产品。而分布式文件系统就很多了,各种开源闭源的产品数得出几十个,在不同的领域各有应用。至于分布式的块存储产品就比较少,也很难做好。我个人认为这个产品形态有点违和,分布式的思想和块存储的设计追求其实是冲突的。前面讲过,块存储主要是图快,一上分布式肯定严重拖后腿,既然都分布开了,节点之间的通信必然增加额外负担,再加上CAP,为了保持一致性牺牲响应速度,得到的好处就是扩展性。这就像把超跑弄个铁索连环,哪里还可能跑出高速?链条比车都重了,穿起来当火车开吗?
而文件存储原来也就是集装箱货车,大家连起来扮火车还是有可行性的。
块存储、文件存储、对象存储的层次关系
应用的角度聊过了,我们再看看这三种存储的一些技术细节,首先看看在系统层级的分布。
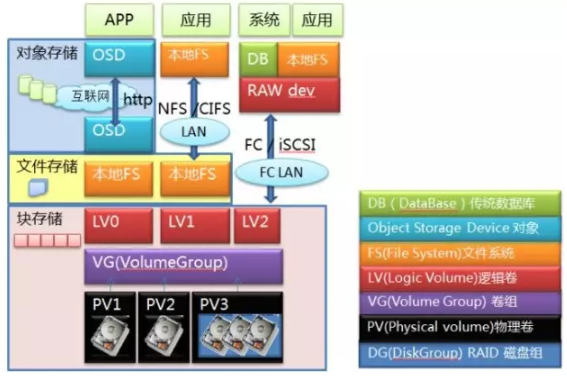
我们从底层往上看,最底层就是硬盘,多个硬盘可以做成RAID组,无论是单个硬盘还是RAID组,都可以做成PV,多个PV物理卷捏在一起构成VG卷组,这就做成一块大蛋糕了。接下来,可以从蛋糕上切下很多块LV逻辑卷,这就到了存储用户最熟悉的卷这层。到这一层为止,数据一直都是以Block块的形式存在的,这时候提供出来的服务就是块存储服务。你可以通过FC协议或者iSCSI协议对卷访问,映射到主机端本地,成为一个裸设备。在主机端可以直接在上面安装数据库,也可以格式化成文件系统后交给应用程序使用,这时候就是一个标准的SAN存储设备的访问模式,网络间传送的是块。
如果不急着访问,也可以在本地做文件系统,之后以NFS/CIFS协议挂载,映射到本地目录,直接以文件形式访问,这就成了NAS访问的模式,在网络间传送的是文件。
如果不走NAS,在本地文件系统上面部署OSD服务端,把整个设备做成一个OSD,这样的节点多来几个,再加上必要的MDS节点,互联网另一端的应用程序再通过HTTP协议直接进行访问,这就变成了对象存储的访问模式。当然对象存储通常不需要专业的存储设备,前面那些LV/VG/PV层也可以统统不要,直接在硬盘上做本地文件系统,之后再做成OSD,这种才是对象存储的标准模式,对象存储的硬件设备通常就用大盘位的服务器。
从系统层级上来说,这三种存储是按照块->文件->对象逐级向上的。文件一定是基于块上面去做,不管是远端还是本地。而对象存储的底层或者说后端存储通常是基于一个本地文件系统(XFS/Ext4..)。这样做是比较合理顺畅的架构。但是大家想法很多,还有各种特异的产品出现,我们逐个来看看:
对象存储除了基于文件,可以直接基于块,但是做这个实现的很少,毕竟你还是得把文件系统的活给干了,自己实现一套元数据管理,也挺麻烦的,目前我只看到Nutanix宣称支持。另外对象存储还能基于对象存储,这就有点尴尬了,就是转一下,何必呢?但是这都不算最奇怪的,最奇怪的是把对象存储放在最底层,那就是这两年大红的Ceph。
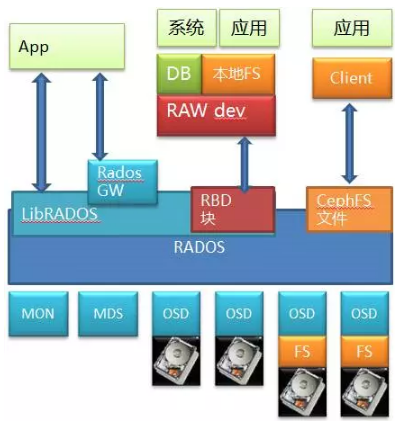
Ceph是个开源的分布式存储,相信类似的架构图大家都见过,我把底层细节也画出来,方便分析。
底层是RADOS,这是个标准的对象存储。以RADOS为基础,Ceph 能够提供文件,块和对象三种存储服务。其中通过RBD提供出来的块存储是比较有价值的地方,毕竟因为市面上开源的分布式块存储少见嘛(以前倒是有个sheepdog,但是现在不当红了)。当然它也通过CephFS模块和相应的私有Client提供了文件服务,这也是很多人认为Ceph是个文件系统的原因。另外它自己原生的对象存储可以通过RadosGW存储网关模块向外提供对象存储服务,并且和对象存储的事实标准Amazon S3以及Swift兼容。所以能看出来这其实是个大一统解决方案,啥都齐全。
上面讲的大家或多或少都有所了解,但底层的RADOS的细节可能会忽略,RADOS也是个标准对象存储,里面也有MDS的元数据管理和OSD的数据存储,而OSD本身是可以基于一个本地文件系统的,比如XFS/EXT4/Brtfs。在早期版本,你在部署Ceph的时候,是不是要给OSD创建数据目录啊?这一步其实就已经在本地文件系统上做操作了(现在的版本Ceph可以直接使用硬盘)。
现在我们来看数据访问路径,如果看Ceph的文件接口,自底层向上,经过了硬盘(块)->文件->对象->文件的路径;如果看RBD的块存储服务,则经过了硬盘(块)->文件->对象->块,也可能是硬盘(块)->对象->块的路径;再看看对象接口(虽然用的不多),则是经过了硬盘(块)->文件->对象或者硬盘(块)->对象的路径。
是不是各种组合差不多齐全了?如果你觉得只有Ceph一个这么玩,再给你介绍另一个狠角色,老牌的开源分布式文件系统GlusterFS也宣布要支持对象存储。它打算使用swift的上层PUT、GET等接口,支持对象存储。这是文件存储去兼容对象存储。对象存储Swift也没闲着,有人在研究Swift和hadoop的兼容性,要知道MapReduce标准是用原生的HDFS做存储的,这相当是对象存储去兼容文件存储,看来混搭真是潮流啊。
虽说现在大家都这么随便结合,但是这三种存储本质上还是有不同的,我们回到计算机的基础课程,从数据结构来看,这三种存储有着根本不同。块存储的数据结构是数组,而文件存储是二叉树(B,B-,B+,B*各种树),对象存储基本上都是哈希表。
数组和二叉树都是老生常谈,没有太多值得说的,而对象存储使用的哈希表也就是常听说的键值(KeyVaule型)存储的核心数据结构,每个对象找一个UID(所谓的“键”KEY),算哈希值(所谓的“值Vaule”)以后和目标对应。找了一个哈希表例子如下:
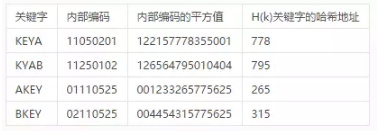
键值对应关系简单粗暴,毕竟算个hash值是很快的,这种扁平化组织形式可以做得非常大,避免了二叉树的深度,对于真·海量的数据存储和大规模访问都能给力支持。所以不仅是对象存储,很多NoSQL的分布式数据库都会使用它,比如Redis,MongoDB,Cassandra 还有Dynamo等等。
顺便说一句,这类NoSQL的出现有点打破了数据库和文件存储的天然屏障,原本关系数据库里面是不会存放太大的数据的,但是现在像MongoDB这种NoSQL都支持直接往里扔大个的“文档”数据,所以从应用角度上,有时候会把对象存储,分布式文件系统,分布式数据库放到一个台面上来比较,这才是混搭。
当然实际上几个开源对象存储比如swift和ceph都是用的一致性哈希,进阶版,最后变成了一个环,首首尾相接,避免了节点故障时大量数据迁移的尴尬,这个几年前写Swift的时候就提过。这里不再深入细节。
(本文首发于2017年5月,文中若涉及相关厂商动态,请以目前最新为准)
转自: talkwithtrend

